Week 5
Machine Learning Part 1
Modeling (Machine Learning)

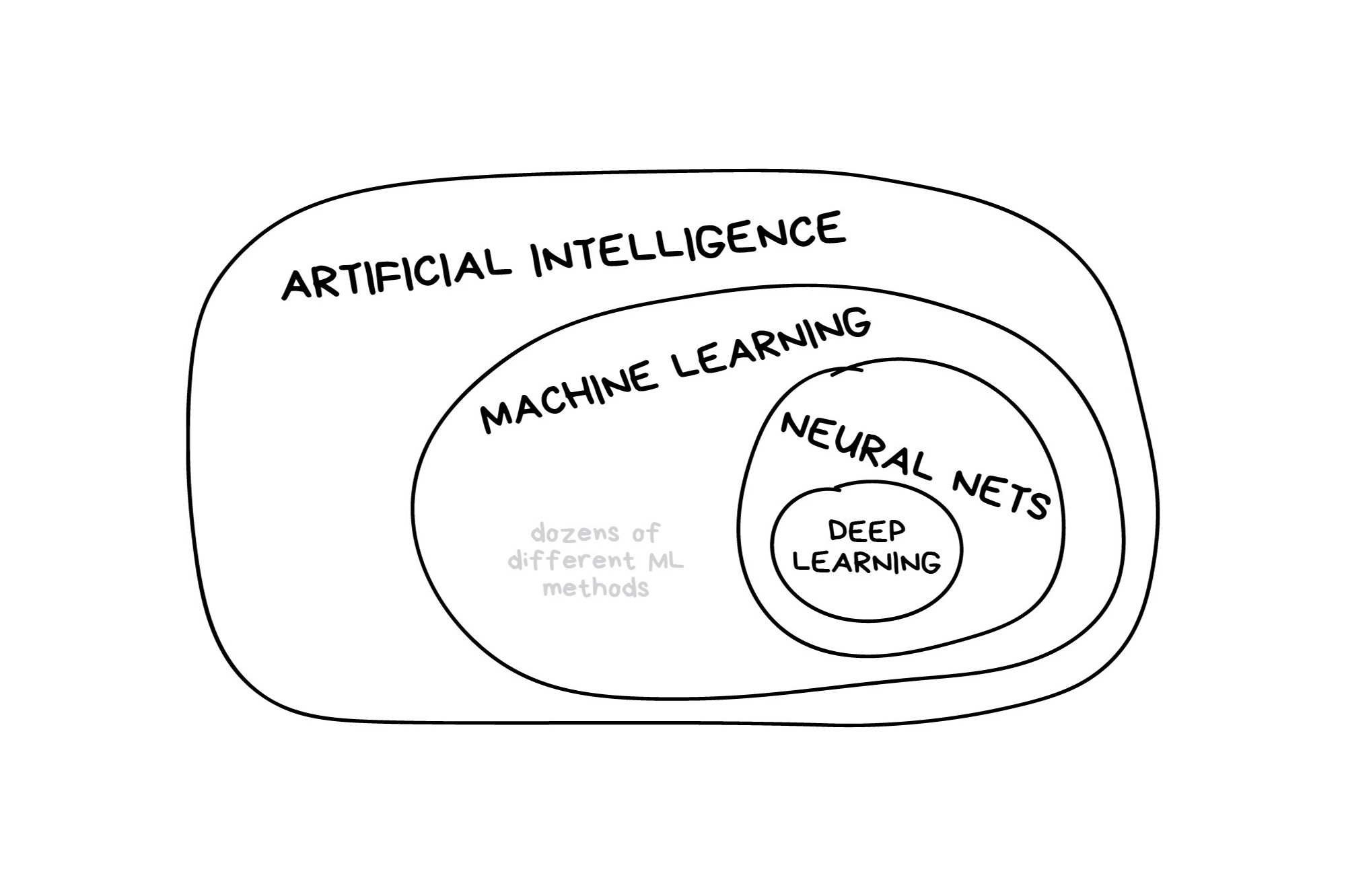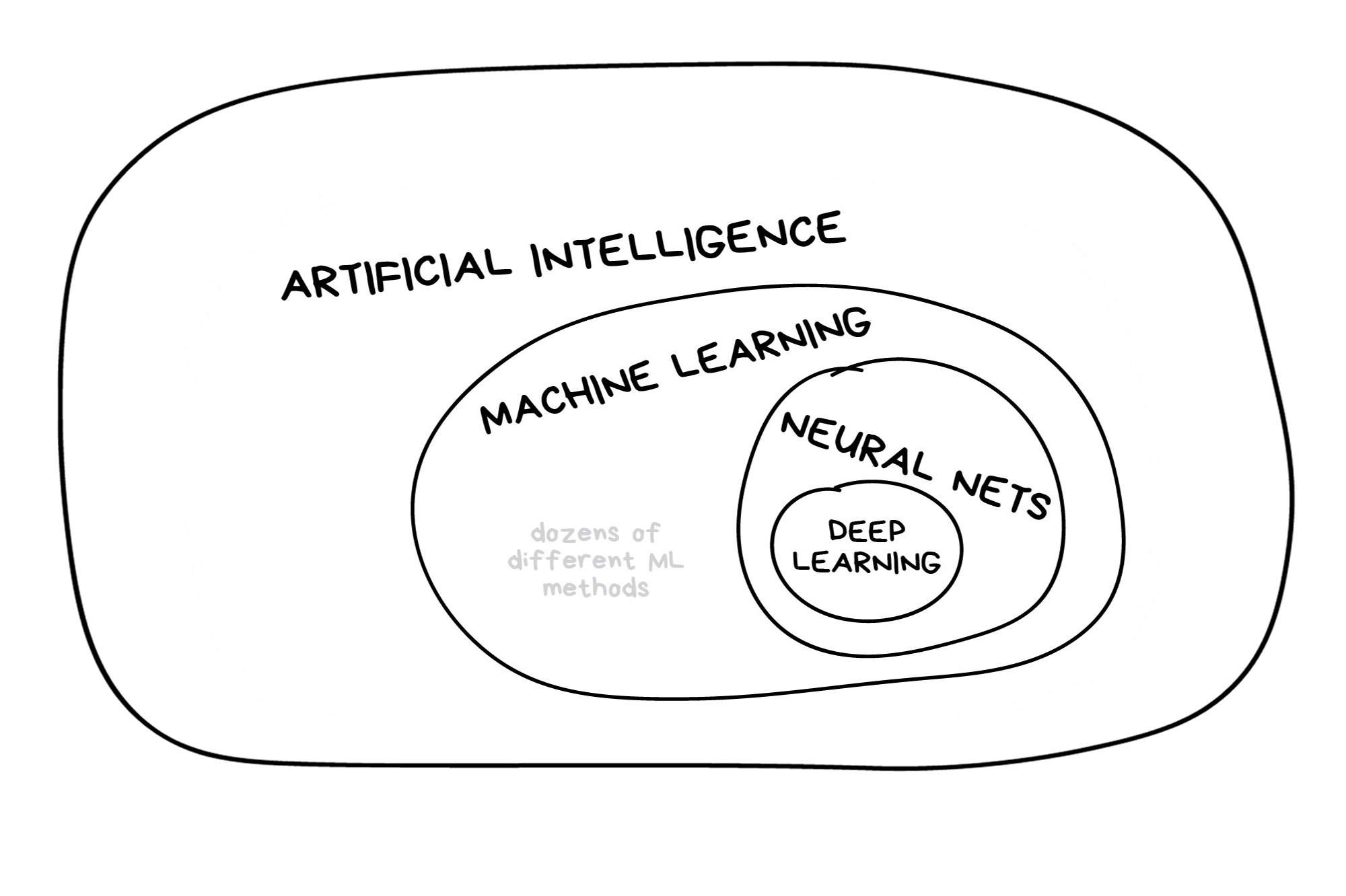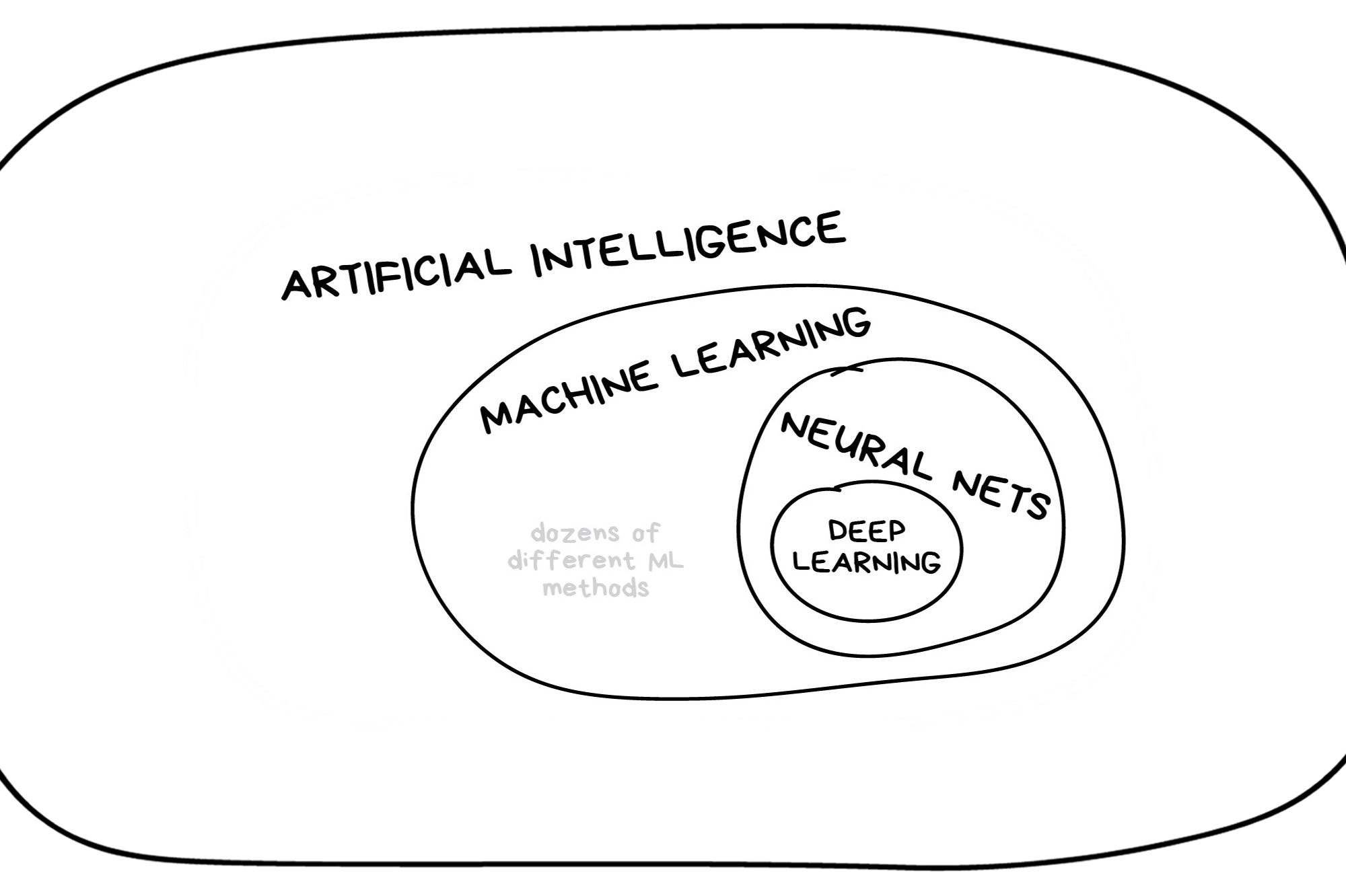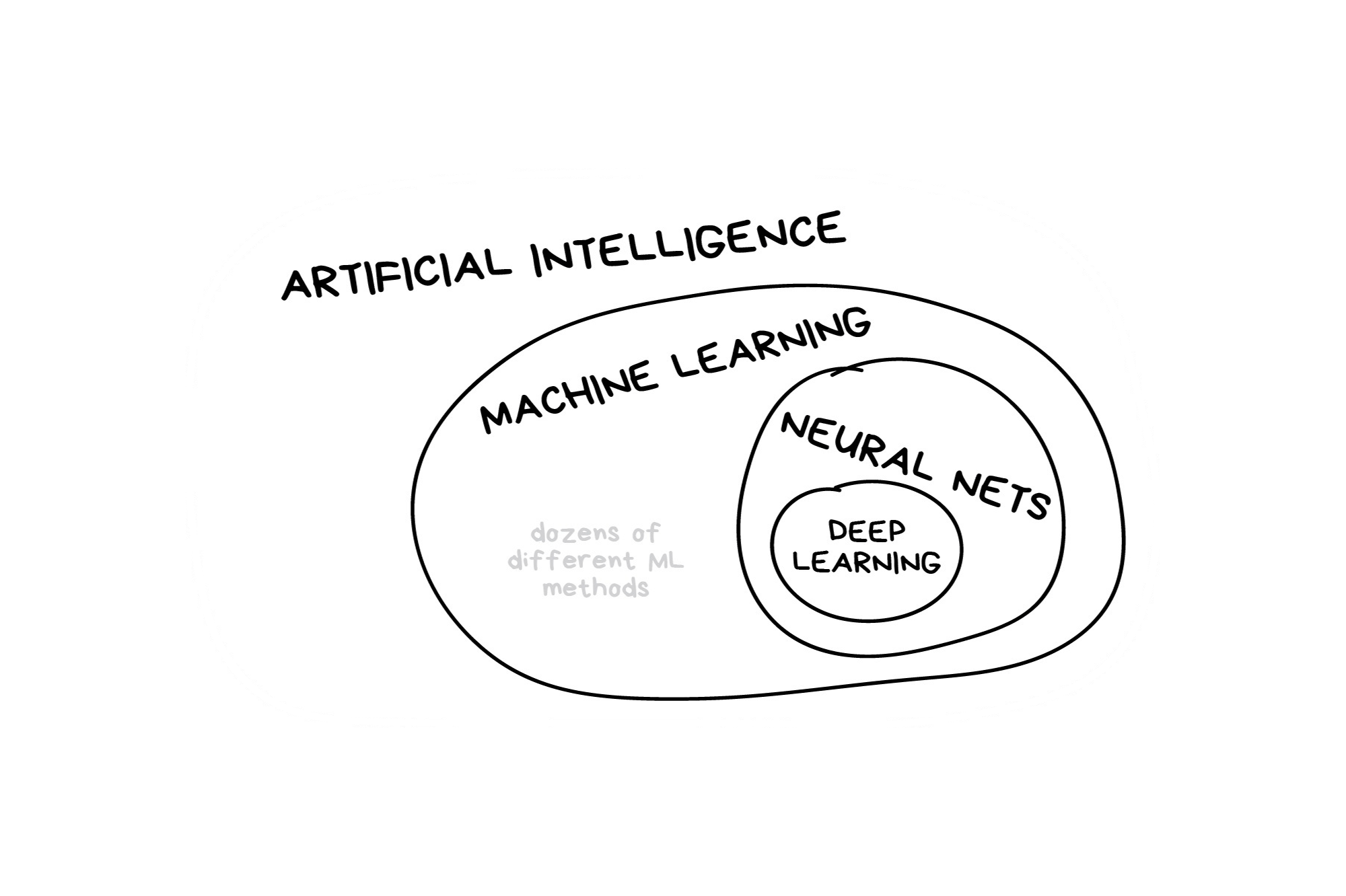
What is machine learning?
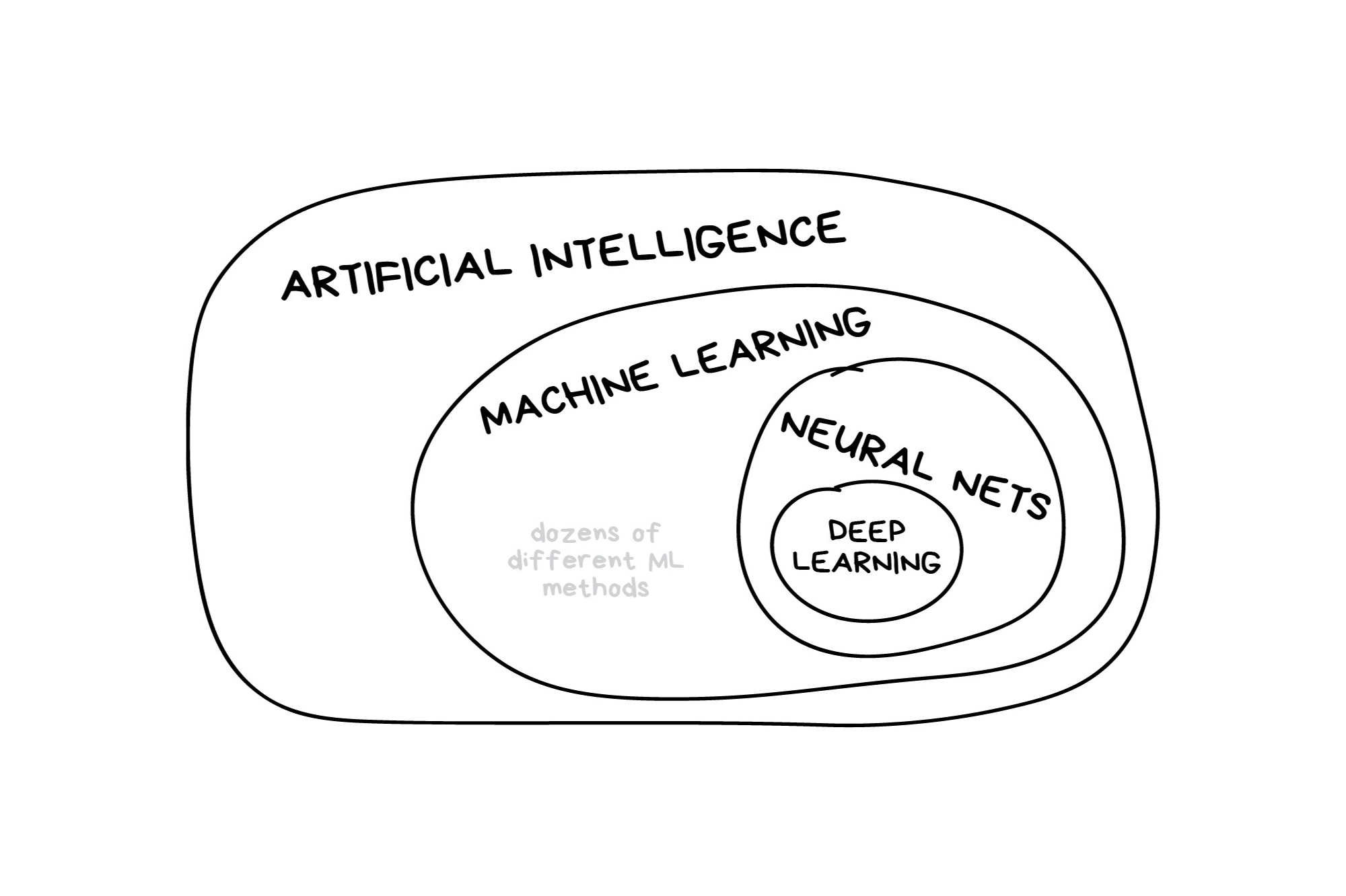
What is machine learning? (2025 edition)
Note
In the early 2010s, “Artificial intelligence” (AI) was largely synonymous with what we’ll refer to as “machine learning” in this workshop. In the late 2010s and early 2020s, AI usually referred to deep learning methods. Since the release of ChatGPT in late 2022, “AI” has come to also encompass large language models (LLMs) / generative models.
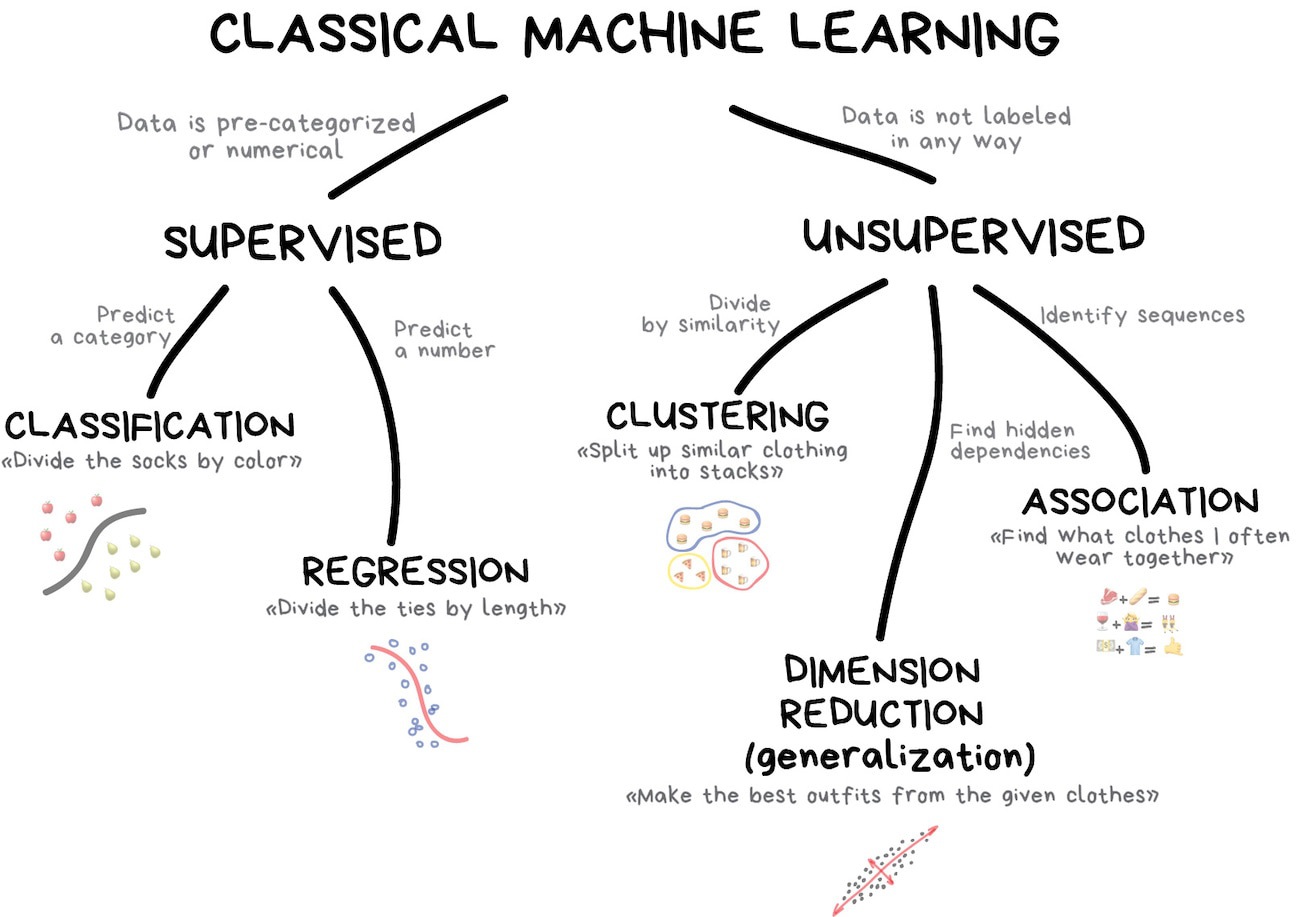
Classic Conceptual Model
The big picture: Road map
Key tidymodels Packages
📦 recipes: Feature engineering and preprocessing
📦 parsnip: Unified interface for model specification
📦 workflows: Streamlined modeling pipelines
📦 tune: Hyperparameter tuning
📦 rsample: Resampling and validation
📦 yardstick: Model evaluation metrics
Recap: broom — tidying model outputs ![]()

broom converts messy model objects into tidy tibbles. Three core functions:
| Function | Returns | Use it when you want to … |
|---|---|---|
tidy() |
One row per model term | Inspect coefficients, p-values, confidence intervals |
glance() |
One row per model | Compare overall fit (R², AIC, log-likelihood, …) |
augment() |
One row per observation | Add predictions, residuals, influence stats to data |
simple_mod <- lm(body_mass_g ~ bill_length_mm + species, data = drop_na(penguins))
tidy(simple_mod) # coefficients table
#> # A tibble: 4 × 5
#> term estimate std.error statistic p.value
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 (Intercept) 200. 272. 0.738 4.61e- 1
#> 2 bill_length_mm 90.3 6.95 13.0 1.97e-31
#> 3 speciesChinstrap -877. 88.7 -9.88 2.46e-20
#> 4 speciesGentoo 597. 76.4 7.81 7.88e-14Predict with your model ![]()
How do you use your new model?
augment()will return the dataset with predictions and residuals added.
#> # A tibble: 333 × 9
#> body_mass_g bill_length_mm species .fitted .resid .hat .sigma .cooksd
#> <int> <dbl> <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 3750 39.1 Adelie 3731. 18.9 0.00688 376. 0.00000443
#> 2 3800 39.5 Adelie 3767. 32.8 0.00701 376. 0.0000136
#> 3 3250 40.3 Adelie 3839. -589. 0.00760 374. 0.00476
#> 4 3450 36.7 Adelie 3514. -64.4 0.00840 376. 0.0000629
#> 5 3650 39.3 Adelie 3749. -99.1 0.00693 376. 0.000123
#> 6 3625 38.9 Adelie 3713. -88.0 0.00685 376. 0.0000956
#> 7 4675 39.2 Adelie 3740. 935. 0.00690 372. 0.0109
#> 8 3200 41.1 Adelie 3912. -712. 0.00863 374. 0.00790
#> 9 3800 38.6 Adelie 3686. 114. 0.00687 376. 0.000161
#> 10 4400 34.6 Adelie 3325. 1075. 0.0130 371. 0.0273
#> # ℹ 323 more rows
#> # ℹ 1 more variable: .std.resid <dbl>What is EDA?
- Exploratory Data Analysis (EDA) is an approach to analyzing datasets to summarize their key characteristics using visualizations and statistical techniques.
- It uncovers patterns, anomalies, and relationships — and guides data cleaning, feature selection, and model choice.
- Today we focus on EDA from a statistical perspective: understanding data properties needed to support modeling assumptions.
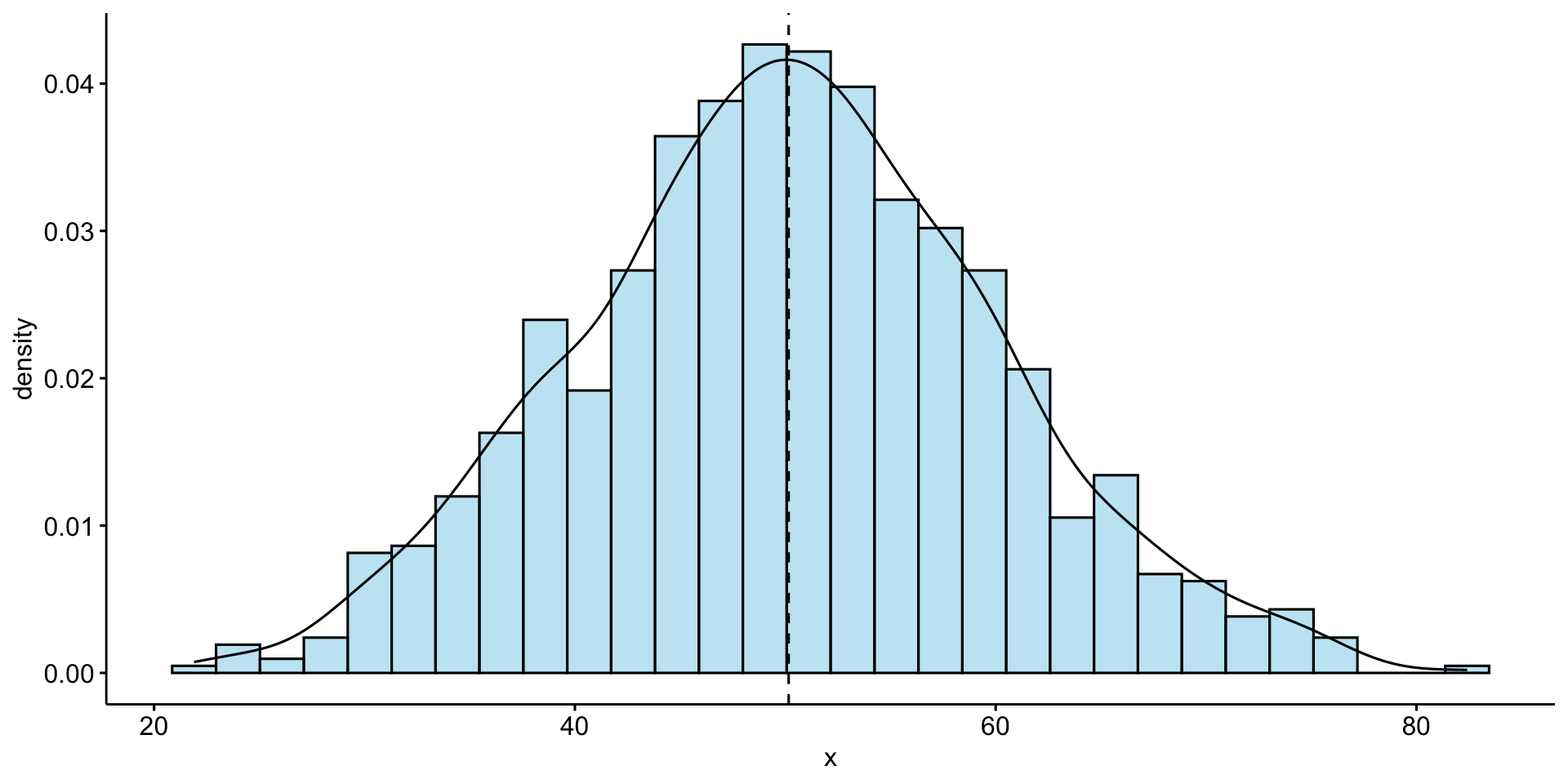
Univariate Analysis – Distribution of Bill Length
Univariate analysis focuses on a single variable at a time.
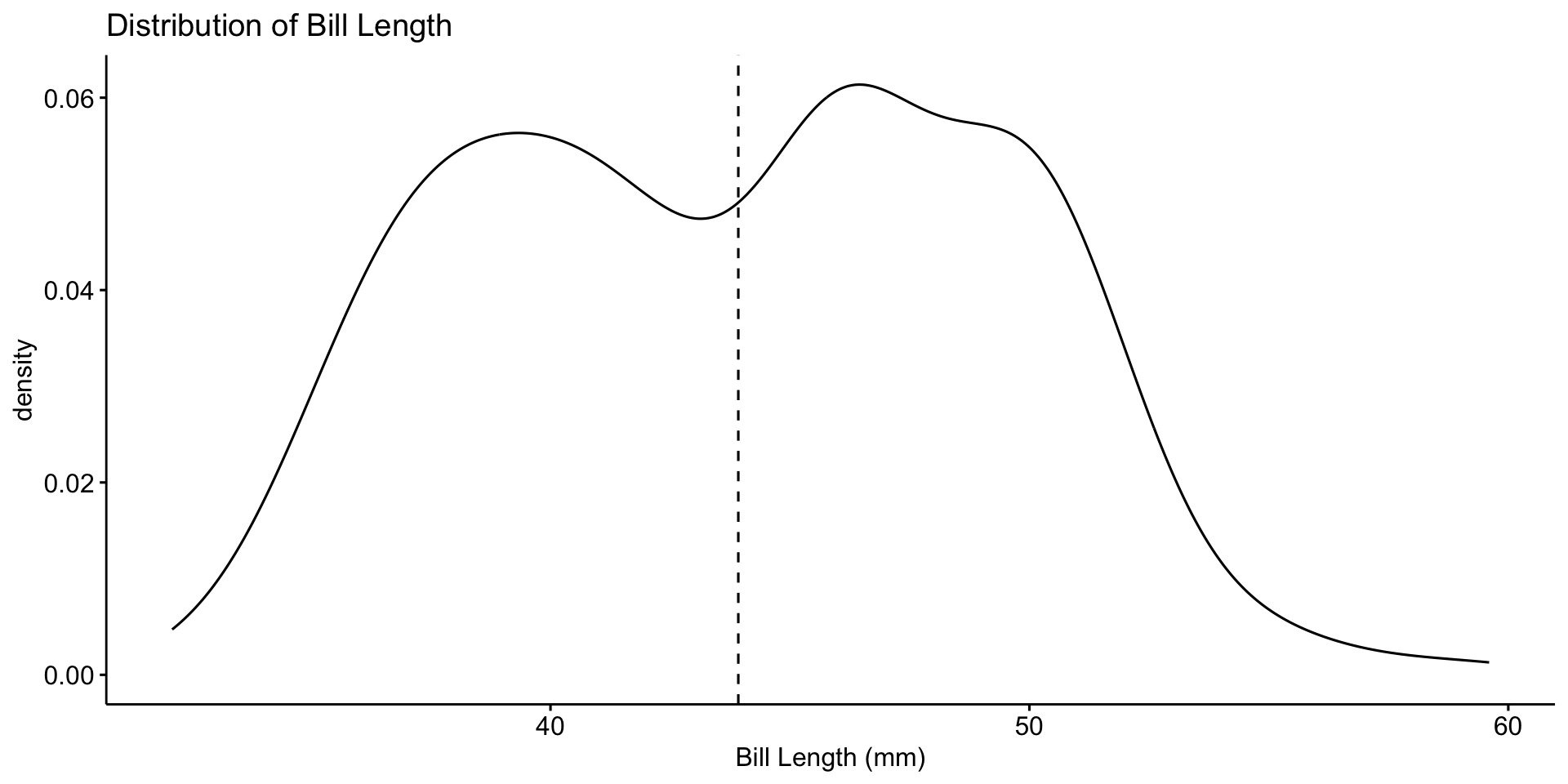
📌 Most bill lengths are between 35–55 mm. Some outliers exist.
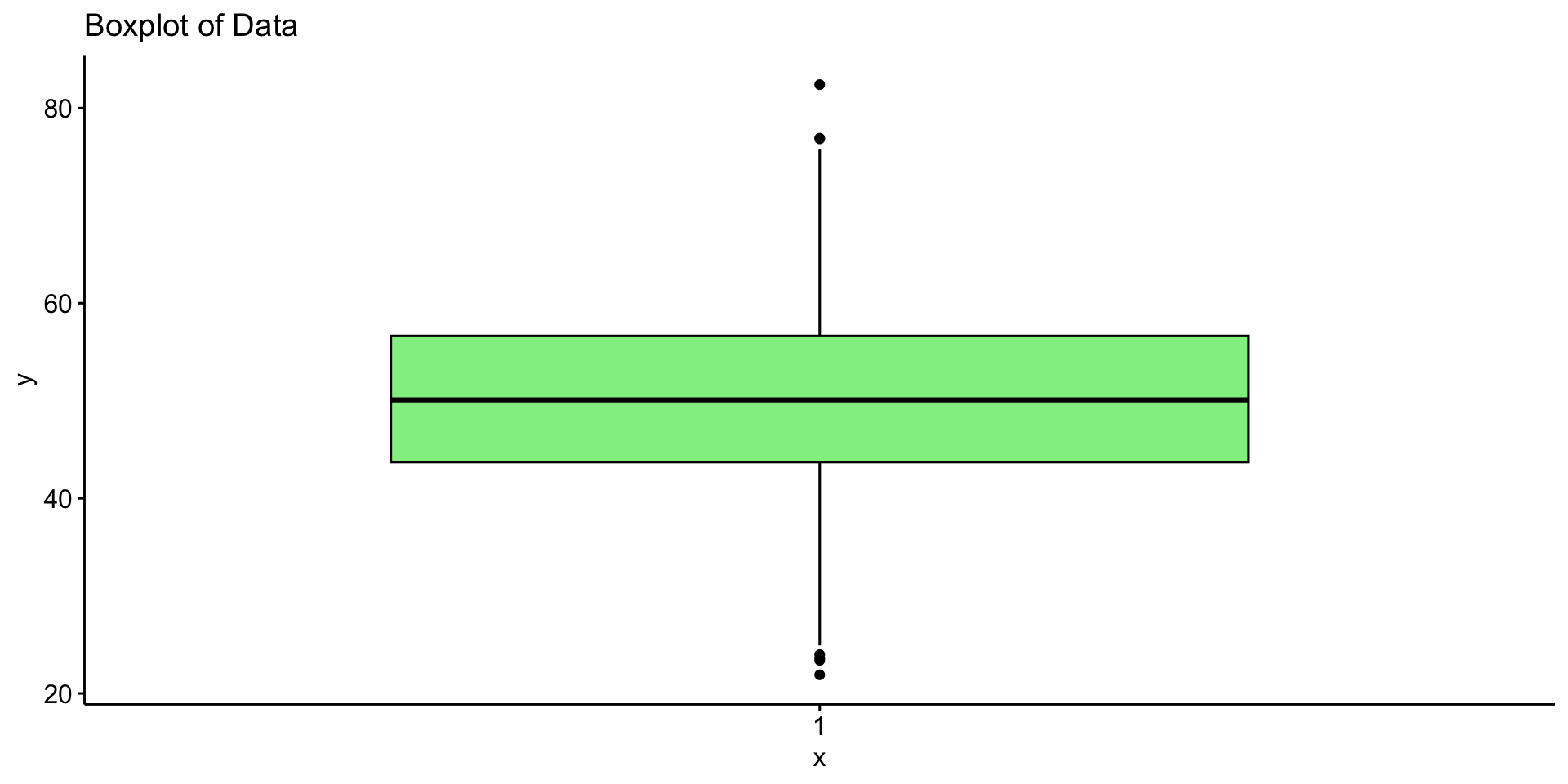
Boxplot for Outlier Detection
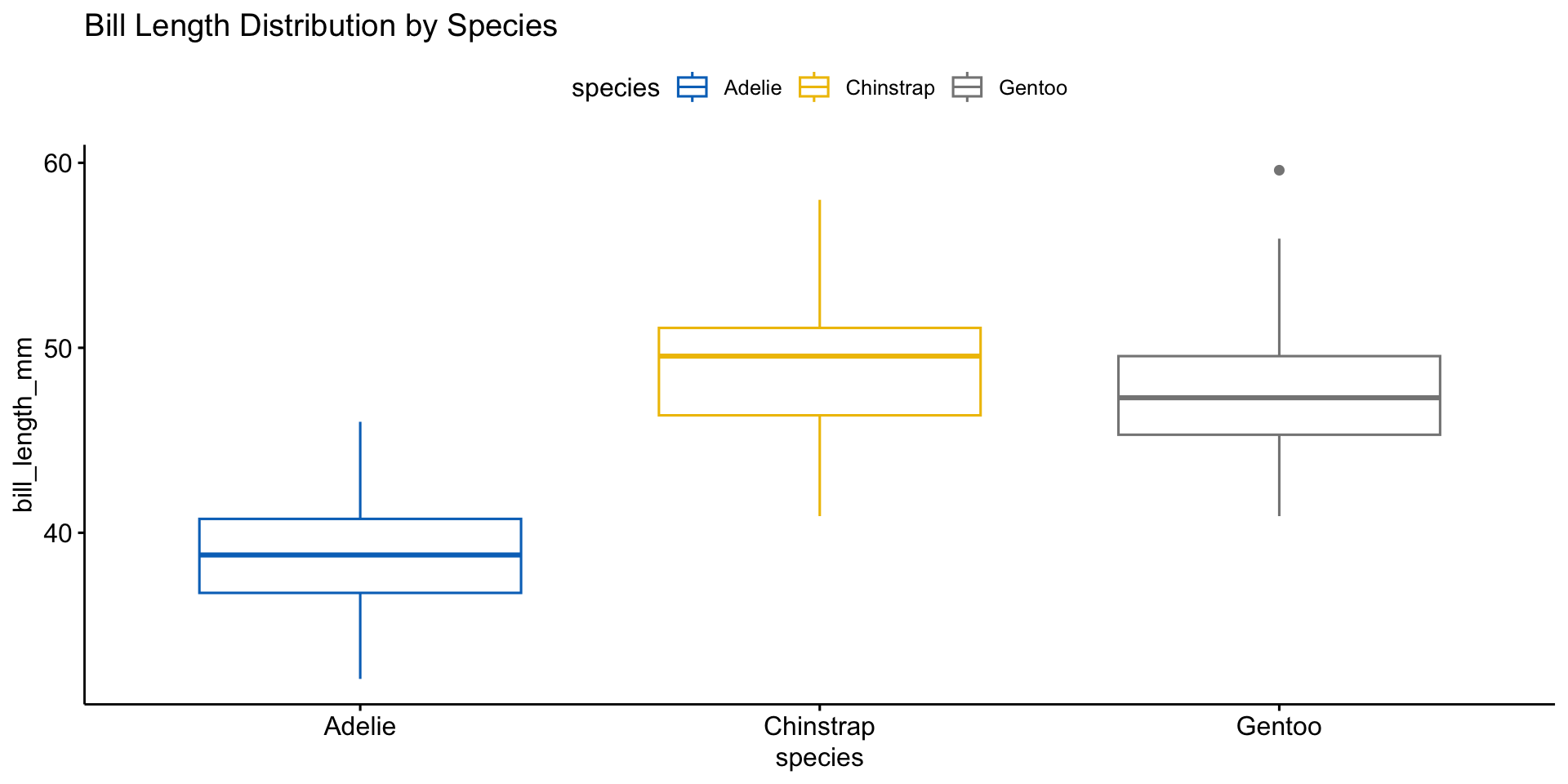
📌 Different species have distinct distributions. Outliers may need further investigation.
Bivariate Analysis
| Variable Types | Plot Type |
|---|---|
| Categorical + Categorical | Bar plot (stacked or side-by-side) |
| Categorical + Continuous | Box plot; bar plot with summary stats |
| Continuous + Continuous | Scatter plot with regression line |
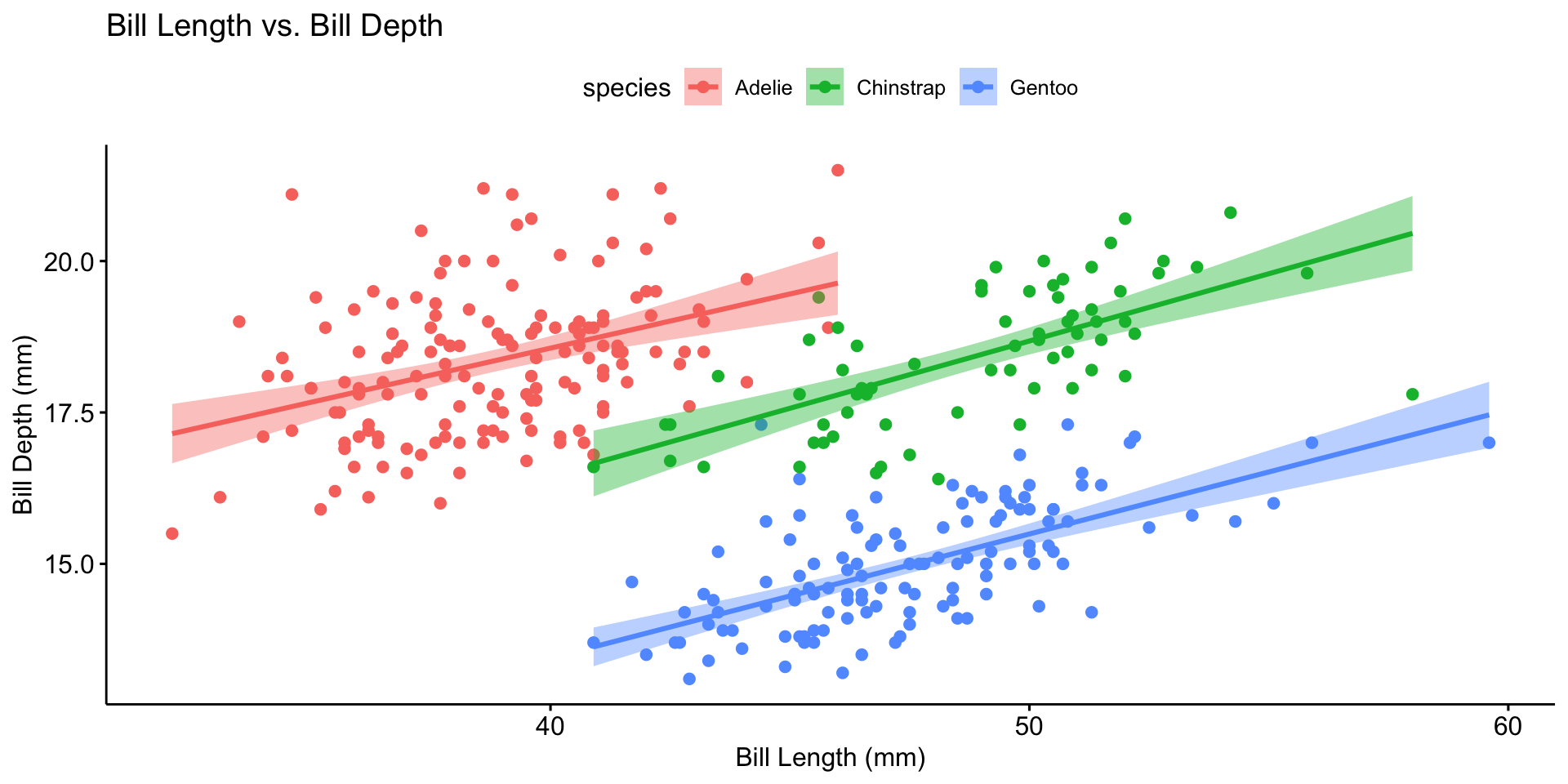
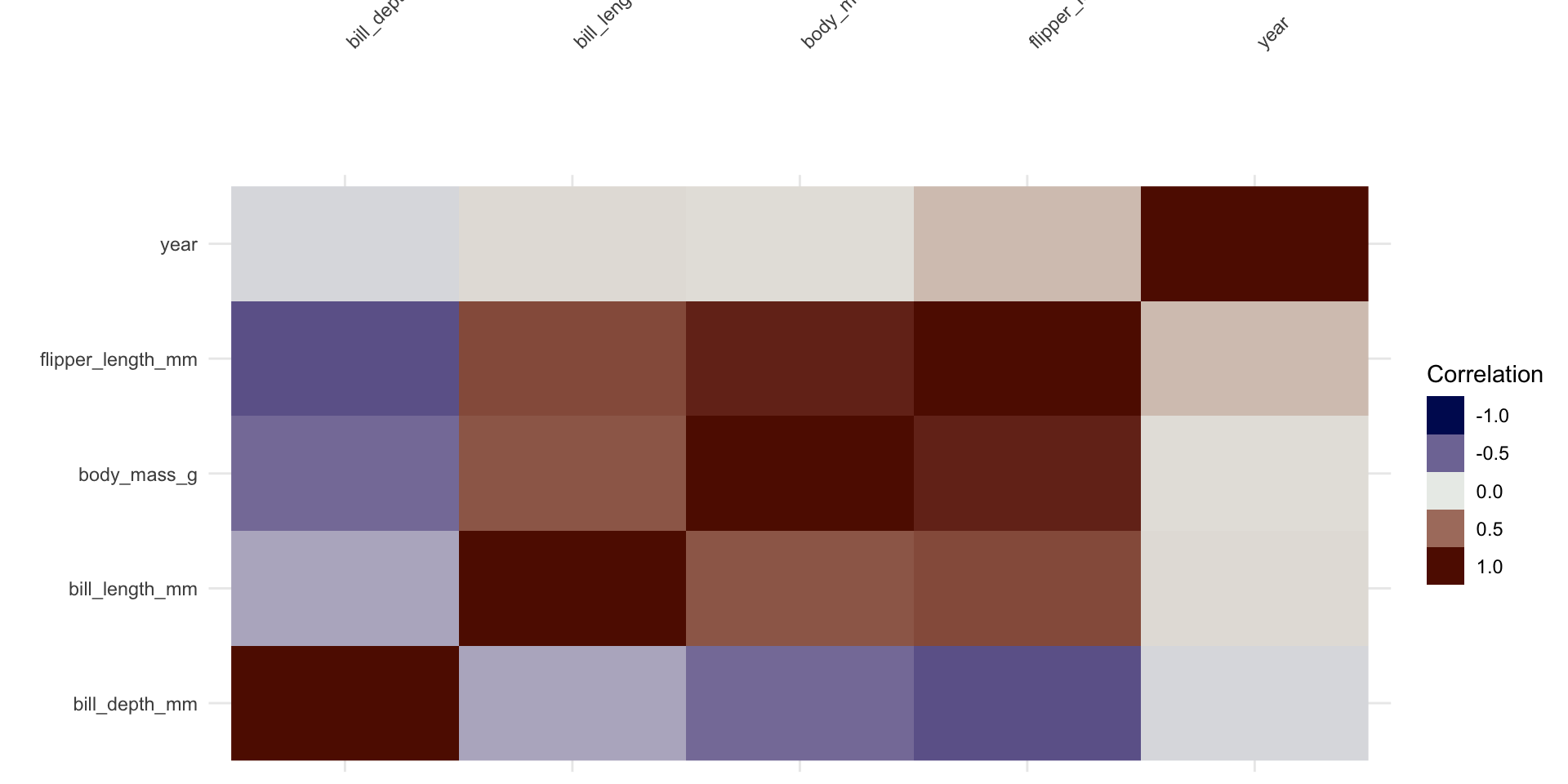
Multivariate Analysis
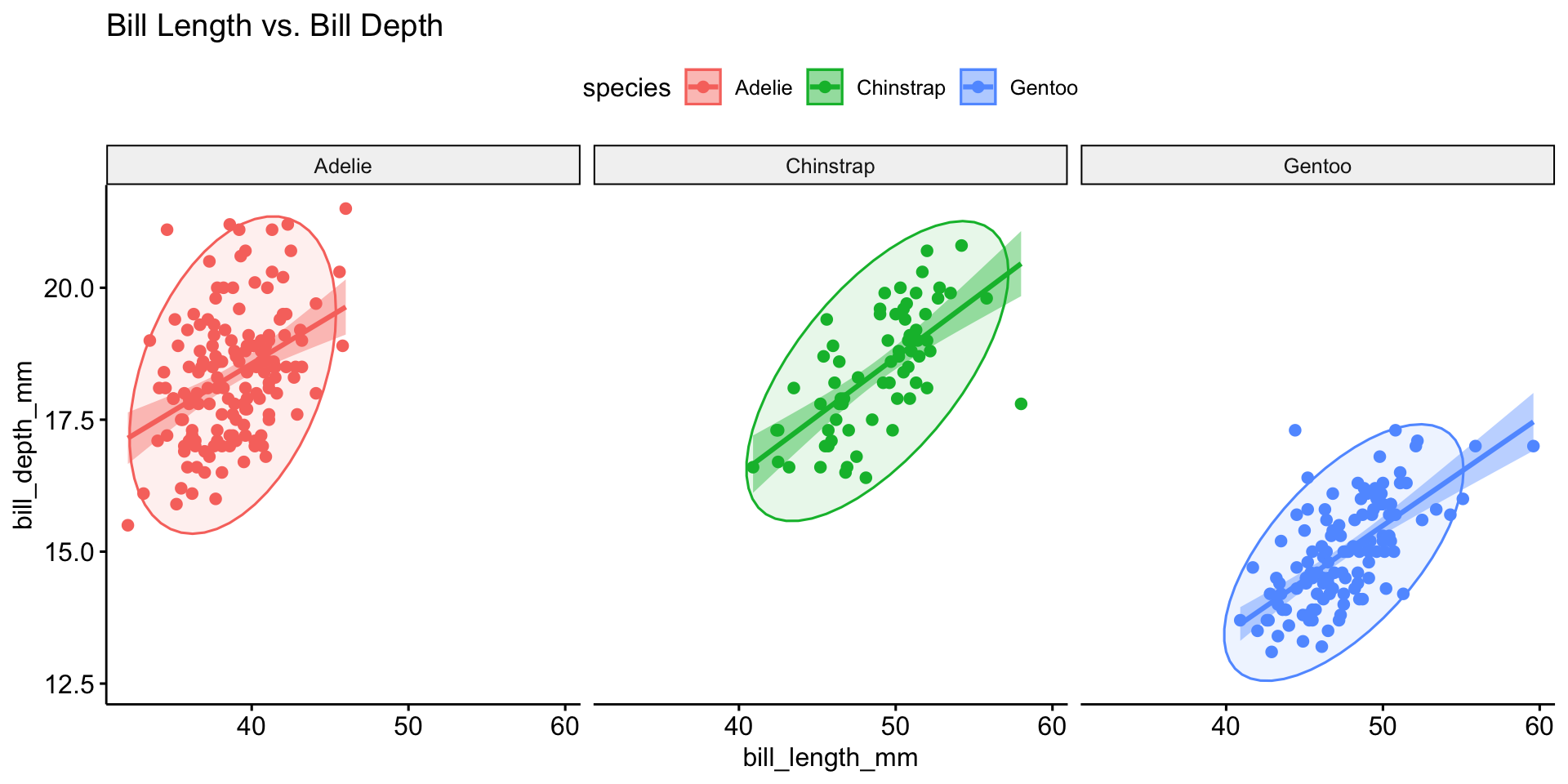
Correlation Analysis
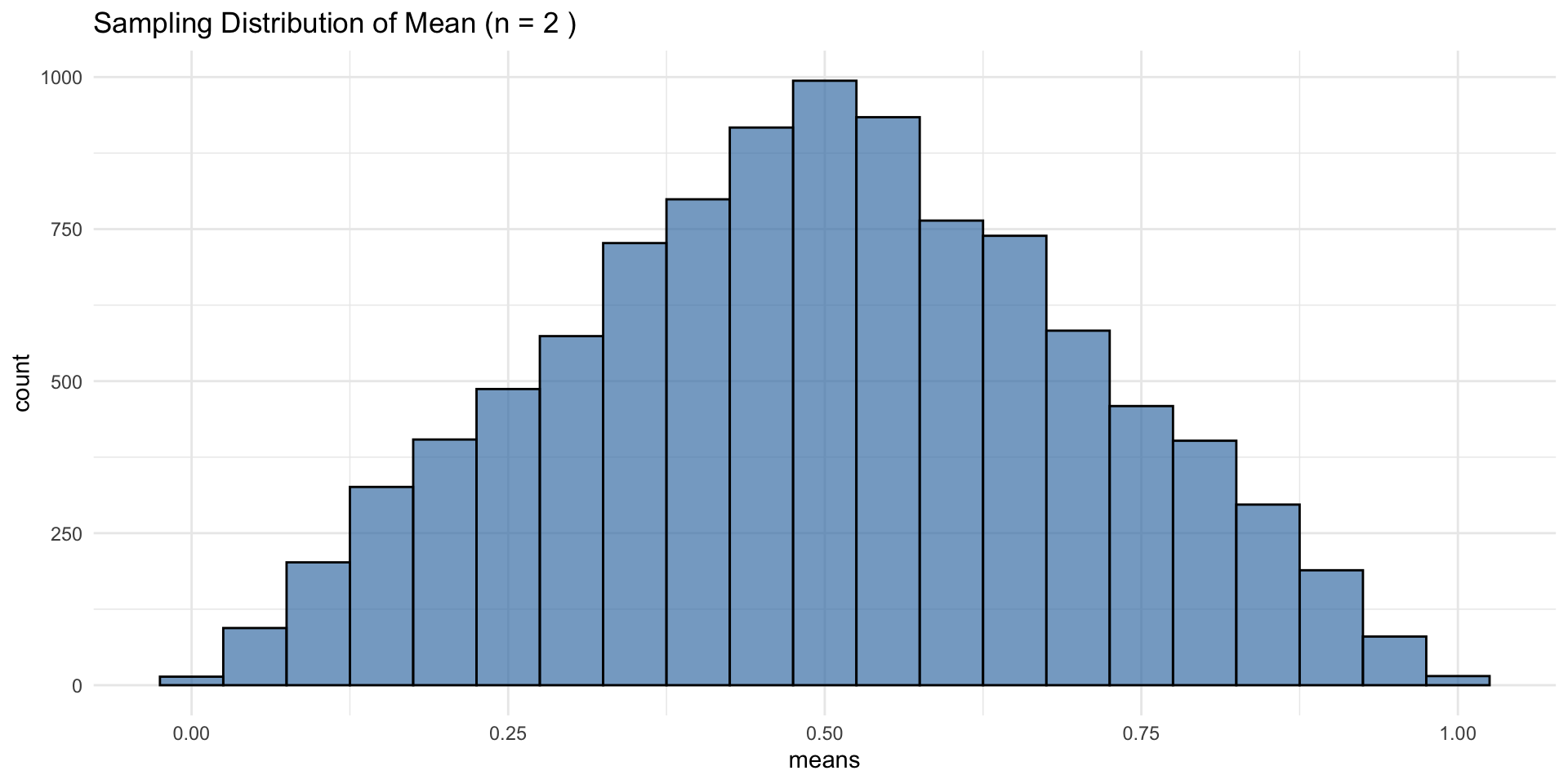
CLT in Action: Uniform Distribution
At n = 2, this may look normal, but the true distribution is triangular—CLT describes convergence, not instant normality
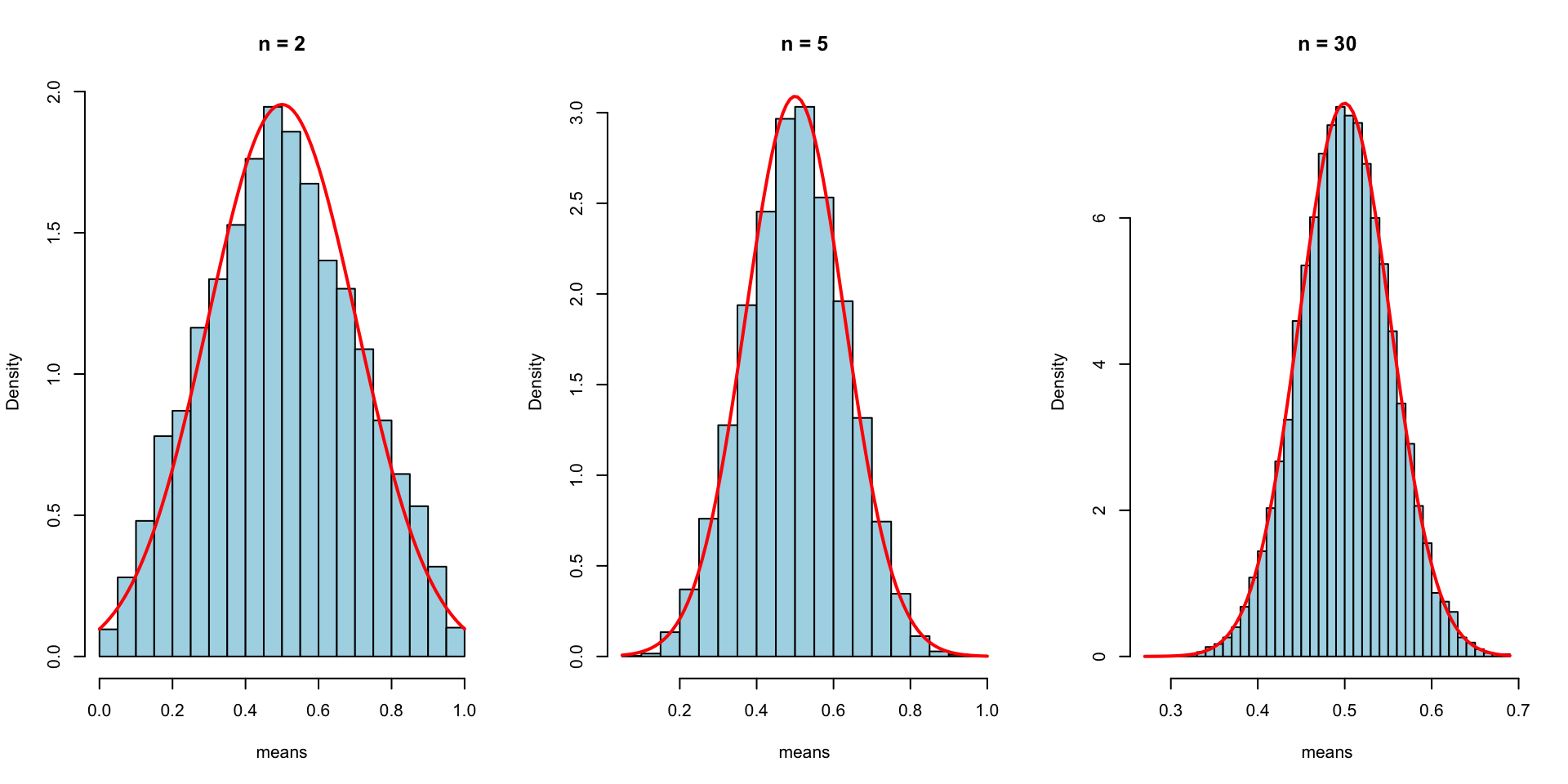
CLT: Increasing Sample Size
As n increases, the distribution of sample means becomes normal even though the original data was uniform.
Properties of a Normal Distribution
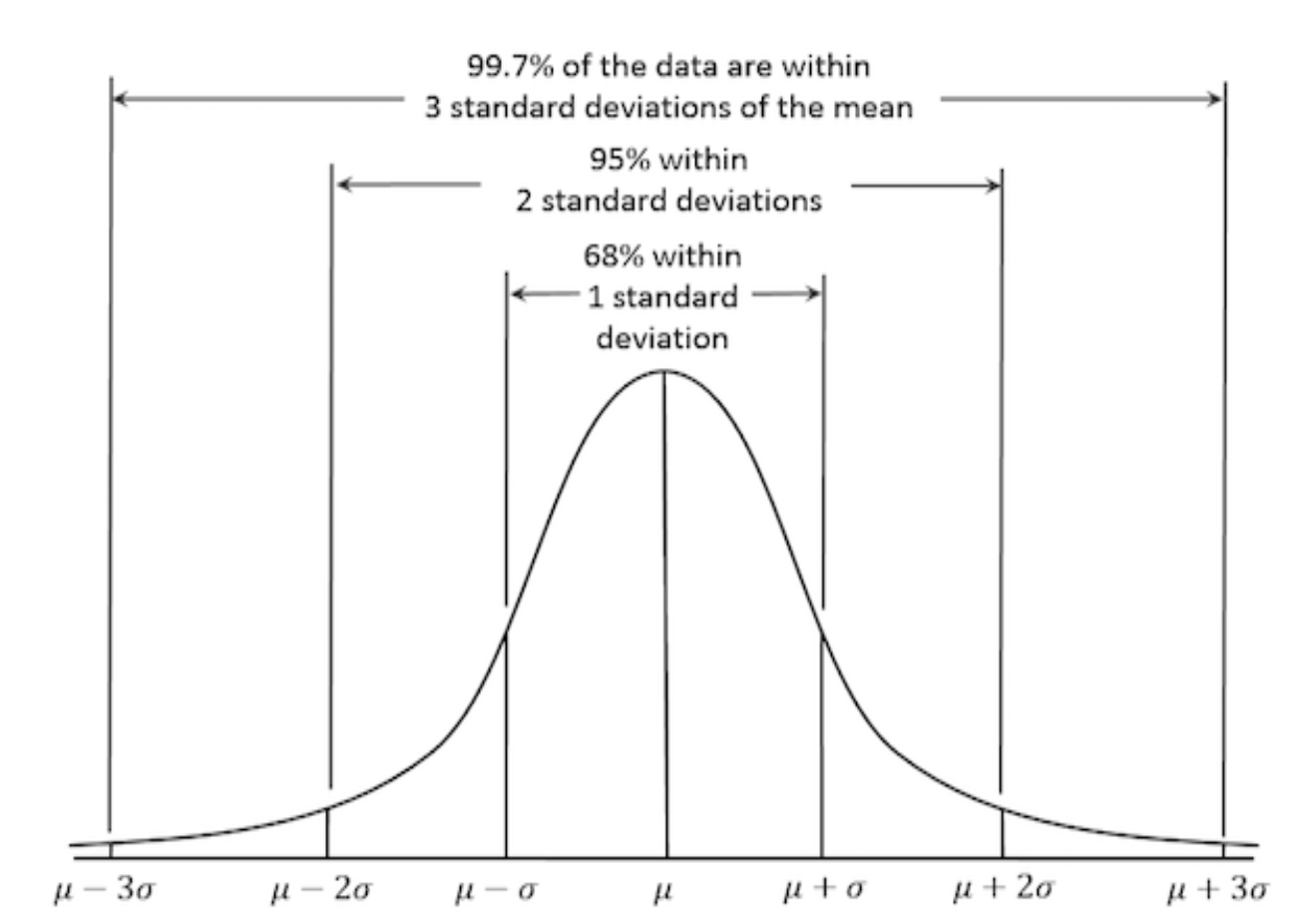
Assessing Normality: Visual Methods
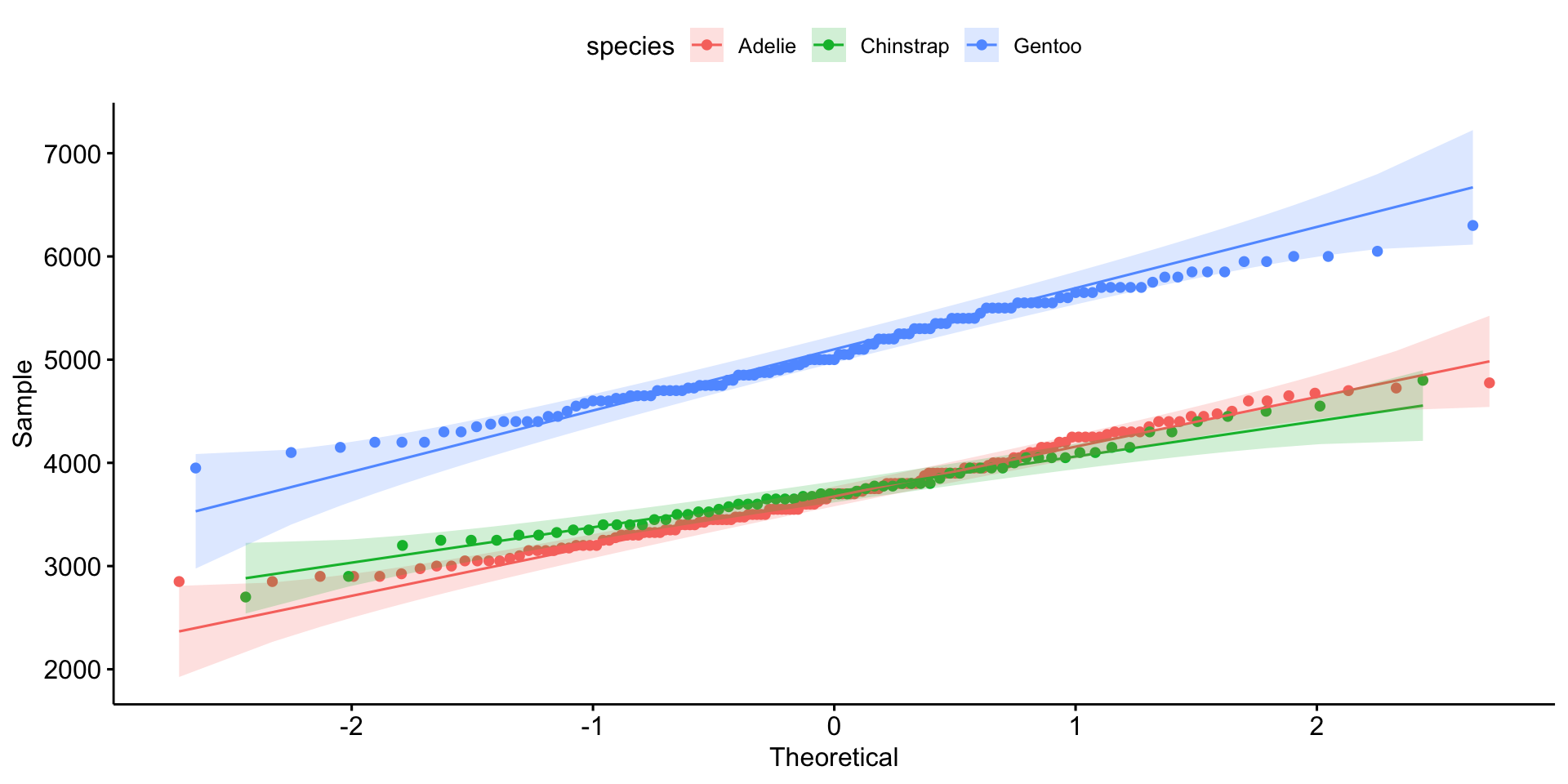
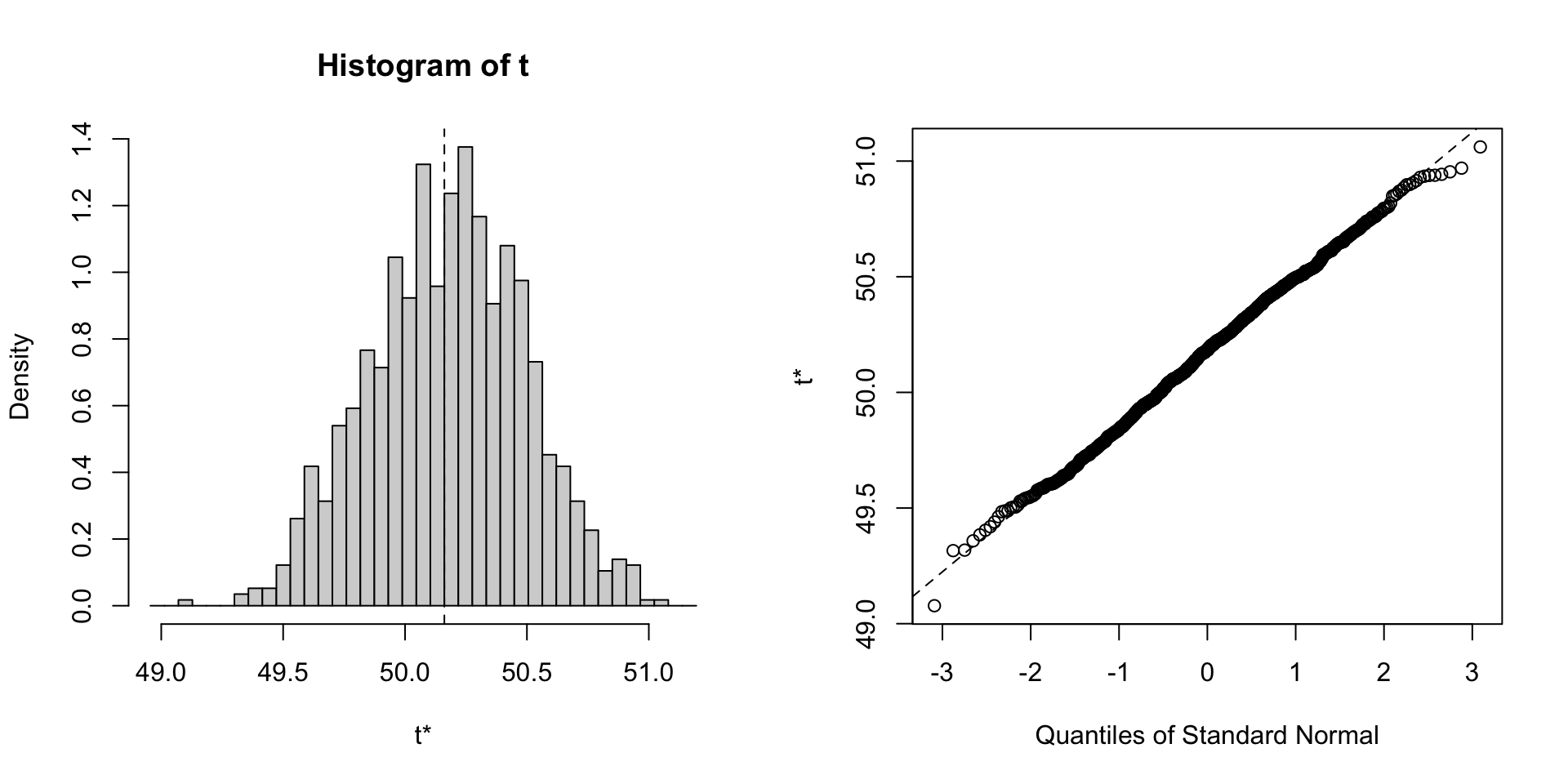
Checking Normality with Q-Q Plots
- Points along the 45-degree line → normally distributed.
- Deviations suggest skewness or outliers.
Option 3 — Bootstrapping
Provides robust estimates without assuming normality:
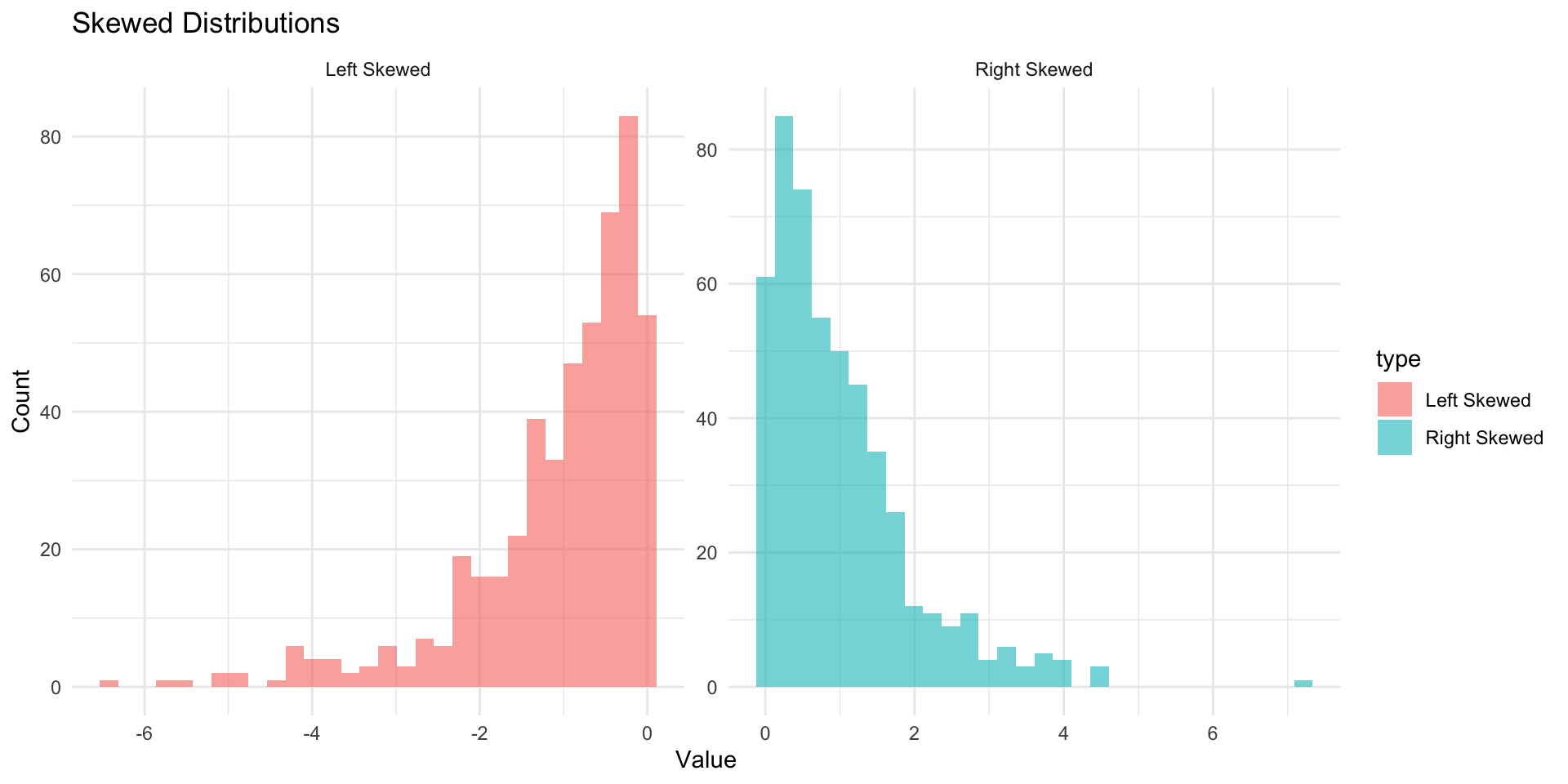
Skewness
Skewness measures the asymmetry of a distribution:
- Positive skew: Longer right tail
- Negative skew: Longer left tail
- Symmetric: No skew (normal)
D’Agostino test for skewness:
Data Budget
In any modeling effort, it’s crucial to evaluate the performance of a model using different validation techniques to ensure a model can generalize to unseen data.
But data is limited even in the age of “big data”.
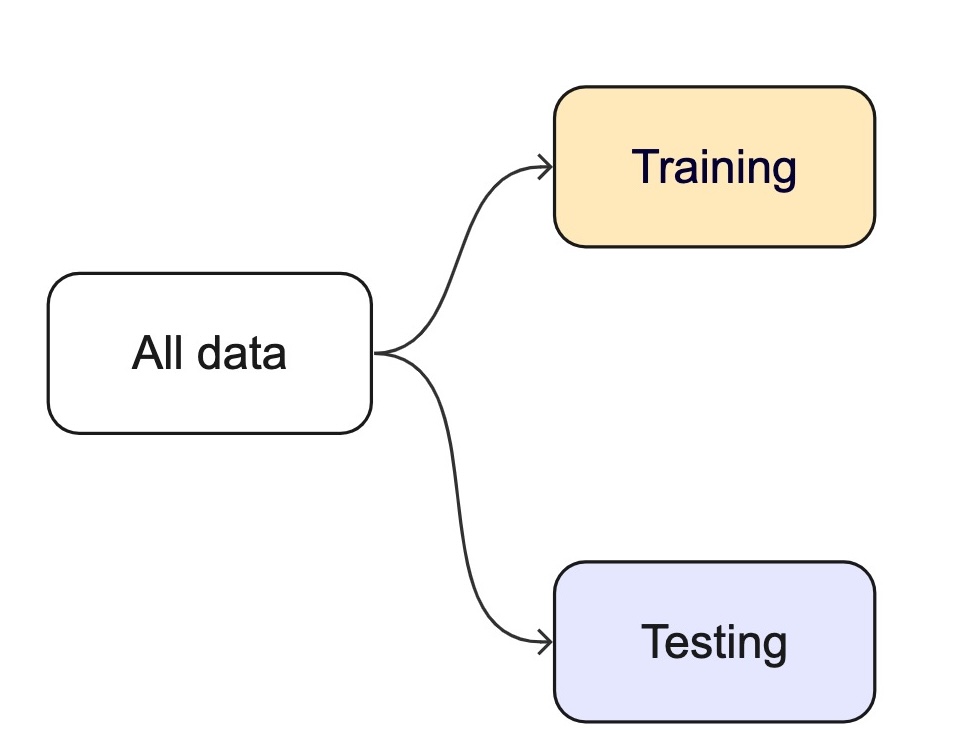
How we split data

Splitting can be handled in many of ways. Typically, we base it off of a “hold out” percentage (e.g. 20%)
These hold out cases are extracted randomly from the data set. (remember seeds?)
- The training set is usually the majority of the data and provides a sandbox for testing different modeling approaches.
The test set is held in reserve until one or two models are chosen.
The test set is then used as the final arbiter to determine the efficacy of the model.
Initial splits ![]()

- In
tidymodels, thersamplepackage provides functions for creating initial splits of data. - The
initial_split()function is used to create a single split of the data. - The
propargument defines the proportion of the data to be used for training. - The default is 0.75, which means 75% of the data will be used for training and 25% for testing.
Accessing the data: ![]()
- Once the data is split, we can access the training and testing data using the
training()andtesting()functions to extract the partitioned data from the full set:
penguins_train <- training(resample_split)
glimpse(penguins_train)
#> Rows: 275
#> Columns: 8
#> $ species <fct> Gentoo, Adelie, Gentoo, Chinstrap, Gentoo, Chinstrap…
#> $ island <fct> Biscoe, Torgersen, Biscoe, Dream, Biscoe, Dream, Dre…
#> $ bill_length_mm <dbl> 46.2, 43.1, 46.2, 45.9, 46.5, 48.1, 45.2, 55.9, 38.1…
#> $ bill_depth_mm <dbl> 14.9, 19.2, 14.4, 17.1, 13.5, 16.4, 17.8, 17.0, 17.0…
#> $ flipper_length_mm <int> 221, 197, 214, 190, 210, 199, 198, 228, 181, 195, 20…
#> $ body_mass_g <int> 5300, 3500, 4650, 3575, 4550, 3325, 3950, 5600, 3175…
#> $ sex <fct> male, male, NA, female, female, female, female, male…
#> $ year <int> 2008, 2009, 2008, 2007, 2007, 2009, 2007, 2009, 2009…penguins_test <- testing(resample_split)
glimpse(penguins_test)
#> Rows: 69
#> Columns: 8
#> $ species <fct> Adelie, Adelie, Adelie, Adelie, Adelie, Adelie, Adel…
#> $ island <fct> Torgersen, Torgersen, Torgersen, Biscoe, Biscoe, Bis…
#> $ bill_length_mm <dbl> NA, 39.3, 36.6, 35.9, 38.8, 37.9, 39.2, 39.6, 36.7, …
#> $ bill_depth_mm <dbl> NA, 20.6, 17.8, 19.2, 17.2, 18.6, 21.1, 17.2, 18.8, …
#> $ flipper_length_mm <int> NA, 190, 185, 189, 180, 172, 196, 196, 187, 205, 187…
#> $ body_mass_g <int> NA, 3650, 3700, 3800, 3800, 3150, 4150, 3550, 3800, …
#> $ sex <fct> NA, male, female, female, male, female, male, female…
#> $ year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2008, 2008…Modeling
Once the data is split, we can decide what type of model to invoke.
Often, users simply pick a well known model type or class for a type of problem (Classic Conceptual Model)
We will learn more about model types and uses next week!
For now, just know that the training data is used to fit a model.
If we are certain about the model, we can use the test data to evaluate the model.
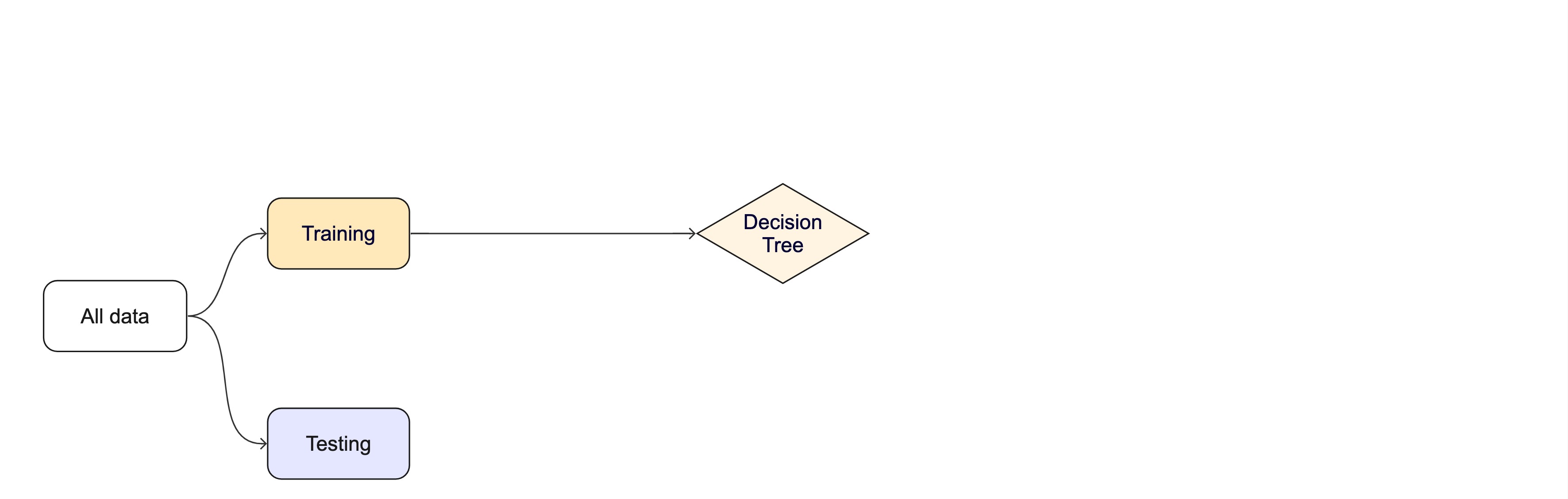
Modeling Options
But, there are many types of models, with different assumptions, behaviors, and qualities, that make some more applicable to a given dataset!
Most models have some type of parameterization, that can often be tuned.
Testing combinations of model and tuning parameters also requires some combination of
training/testingsplits.
Modeling Options
What if we want to compare more models?
And/or more model configurations?
And we want to understand if these are important differences?
How can we use the training data to compare and evaluate different models? 🤔
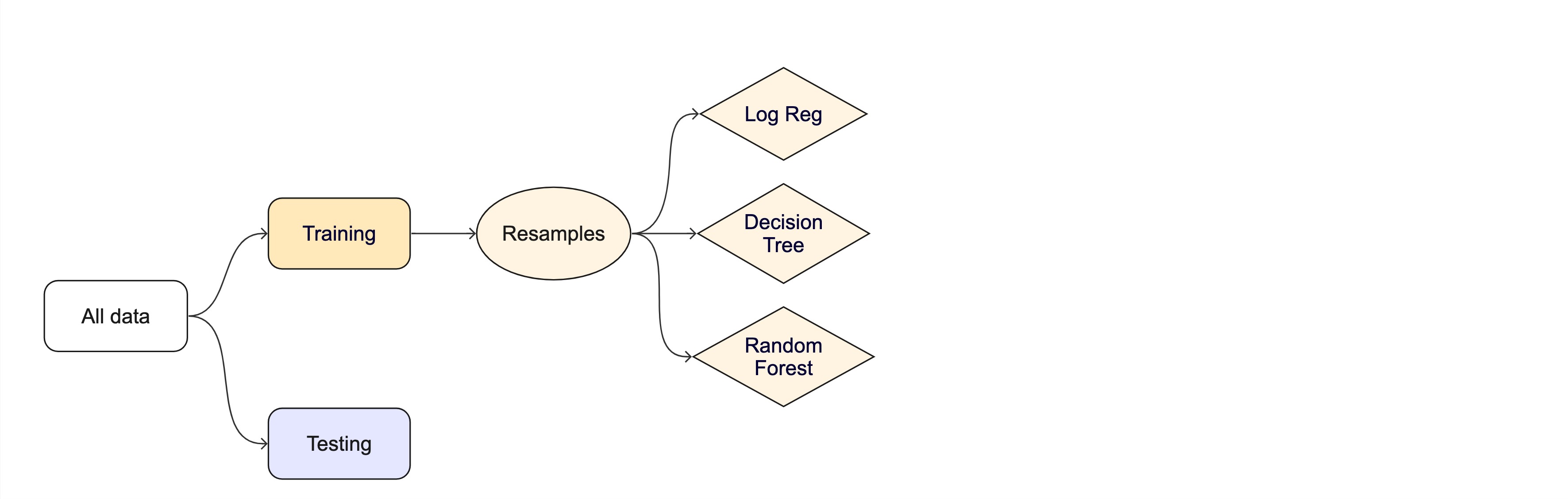
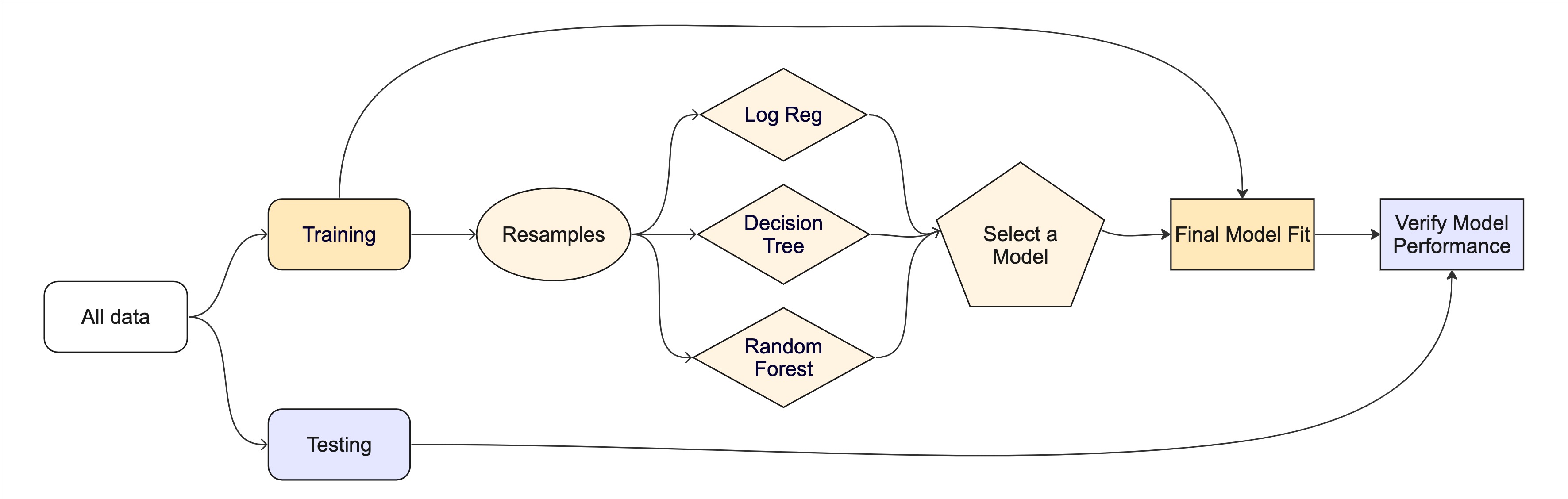
Resampling
Testing combinations of model and tuning parameters also requires some combination of
training/testingsplits.Resampling methods, such as cross-validation and bootstrapping, are empirical simulation systems that help facilitate this.
They create a series of data sets similar to the initial
training/testingsplit.In the first level of the diagram to the right, we first split the original data into
training/testingsets. Then, the training set is chosen for resampling.

Cross-validation

Cross-validation

Cross-validation ![]()
penguins_train |> glimpse()
#> Rows: 275
#> Columns: 8
#> $ species <fct> Gentoo, Adelie, Gentoo, Chinstrap, Gentoo, Chinstrap…
#> $ island <fct> Biscoe, Torgersen, Biscoe, Dream, Biscoe, Dream, Dre…
#> $ bill_length_mm <dbl> 46.2, 43.1, 46.2, 45.9, 46.5, 48.1, 45.2, 55.9, 38.1…
#> $ bill_depth_mm <dbl> 14.9, 19.2, 14.4, 17.1, 13.5, 16.4, 17.8, 17.0, 17.0…
#> $ flipper_length_mm <int> 221, 197, 214, 190, 210, 199, 198, 228, 181, 195, 20…
#> $ body_mass_g <int> 5300, 3500, 4650, 3575, 4550, 3325, 3950, 5600, 3175…
#> $ sex <fct> male, male, NA, female, female, female, female, male…
#> $ year <int> 2008, 2009, 2008, 2007, 2007, 2009, 2007, 2009, 2009…nrow(penguins_train) * 1/10
#> [1] 27.5
vfold_cv(penguins_train, v = 10) # v = 10 is default
#> # 10-fold cross-validation
#> # A tibble: 10 × 2
#> splits id
#> <list> <chr>
#> 1 <split [247/28]> Fold01
#> 2 <split [247/28]> Fold02
#> 3 <split [247/28]> Fold03
#> 4 <split [247/28]> Fold04
#> 5 <split [247/28]> Fold05
#> 6 <split [248/27]> Fold06
#> 7 <split [248/27]> Fold07
#> 8 <split [248/27]> Fold08
#> 9 <split [248/27]> Fold09
#> 10 <split [248/27]> Fold10
Cross-validation ![]()
What is in this?
Note
Here is another example of a list column enabling the storage of non-atomic types in tibble
Important
Set the seed when creating resamples
Bootstrapping

Bootstrapping ![]()
set.seed(3214)
bootstraps(penguins_train)
#> # Bootstrap sampling
#> # A tibble: 25 × 2
#> splits id
#> <list> <chr>
#> 1 <split [275/96]> Bootstrap01
#> 2 <split [275/105]> Bootstrap02
#> 3 <split [275/108]> Bootstrap03
#> 4 <split [275/111]> Bootstrap04
#> 5 <split [275/102]> Bootstrap05
#> 6 <split [275/98]> Bootstrap06
#> 7 <split [275/92]> Bootstrap07
#> 8 <split [275/97]> Bootstrap08
#> 9 <split [275/100]> Bootstrap09
#> 10 <split [275/99]> Bootstrap10
#> # ℹ 15 more rowsMonte Carlo Cross-Validation ![]()
set.seed(322)
mc_cv(penguins_train, times = 10)
#> # Monte Carlo cross-validation (0.75/0.25) with 10 resamples
#> # A tibble: 10 × 2
#> splits id
#> <list> <chr>
#> 1 <split [206/69]> Resample01
#> 2 <split [206/69]> Resample02
#> 3 <split [206/69]> Resample03
#> 4 <split [206/69]> Resample04
#> 5 <split [206/69]> Resample05
#> 6 <split [206/69]> Resample06
#> 7 <split [206/69]> Resample07
#> 8 <split [206/69]> Resample08
#> 9 <split [206/69]> Resample09
#> 10 <split [206/69]> Resample10Validation set ![]()
A validation set is just another type of resample
The whole game - status update
Data on forests in Washington
- The U.S. Forest Service maintains ML models to predict whether a plot of land is “forested.”
- This classification is important for all sorts of research, legislation, and land management purposes.
- Plots are typically remeasured every 10 years and this dataset contains the most recent measurement per plot.
- Type
?forestedto learn more about this dataset, including references.

Data on forests in Washington
One observation from each of 7,107 6000-acre hexagons in Washington state.
A nominal outcome,
forested, with levels"Yes"and"No", measured on-the-ground (expensive, slow).
18 remotely-sensed and easily-accessible predictors (cheap, fast, wall-to-wall coverage).
The ML framing: use cheap, abundant predictors to estimate an expensive ground-truth label so the Forest Service can predict forest cover without sending a crew to every hexagon.

Data splitting and spending
The initial split ![]()
Accessing the data ![]()
K-Fold Cross-Validation ![]()
# Load the dataset
set.seed(123)
# Create a 10-fold cross-validation object
(forested_folds <- vfold_cv(forested_train, v = 10))
#> # 10-fold cross-validation
#> # A tibble: 10 × 2
#> splits id
#> <list> <chr>
#> 1 <split [5116/569]> Fold01
#> 2 <split [5116/569]> Fold02
#> 3 <split [5116/569]> Fold03
#> 4 <split [5116/569]> Fold04
#> 5 <split [5116/569]> Fold05
#> 6 <split [5117/568]> Fold06
#> 7 <split [5117/568]> Fold07
#> 8 <split [5117/568]> Fold08
#> 9 <split [5117/568]> Fold09
#> 10 <split [5117/568]> Fold10Challenge
- All of these models have different syntax and functions
- How do you keep track of all of them?
- How do you know which one to use?
- How would you compare them?
Comparing 3-5 of these models is a lot of work using functions for diverse packages.
The tidymodels advantage
- In the
tidymodelsframework, all models are created using the same syntax:- This makes it easy to compare models
- This makes it easy to switch between models
- This makes it easy to use the same model with different engines (packages)
- The
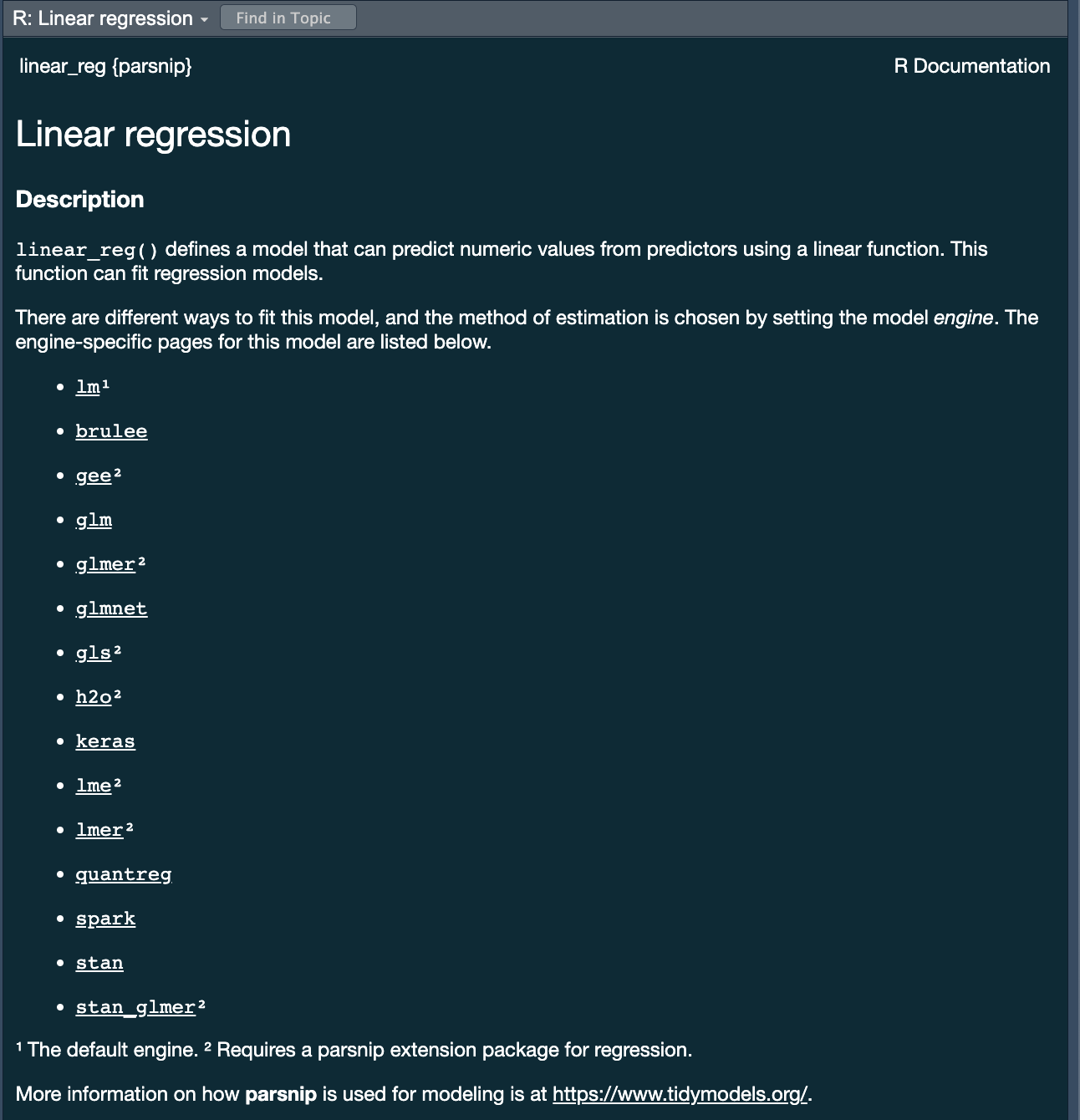
parsnippackage provides a consistent interface to many models - For example, to fit a linear model you would be able to access the
linear_reg()function
A tidymodels prediction will … ![]()

- always be inside a tibble
- have column names and types that are unsurprising and predictable
- ensure the number of rows in
new_dataand the output are the same
To specify a model ![]()

- Choose a model
- Specify an engine
- Set the mode
Specify a model: Type ![]()
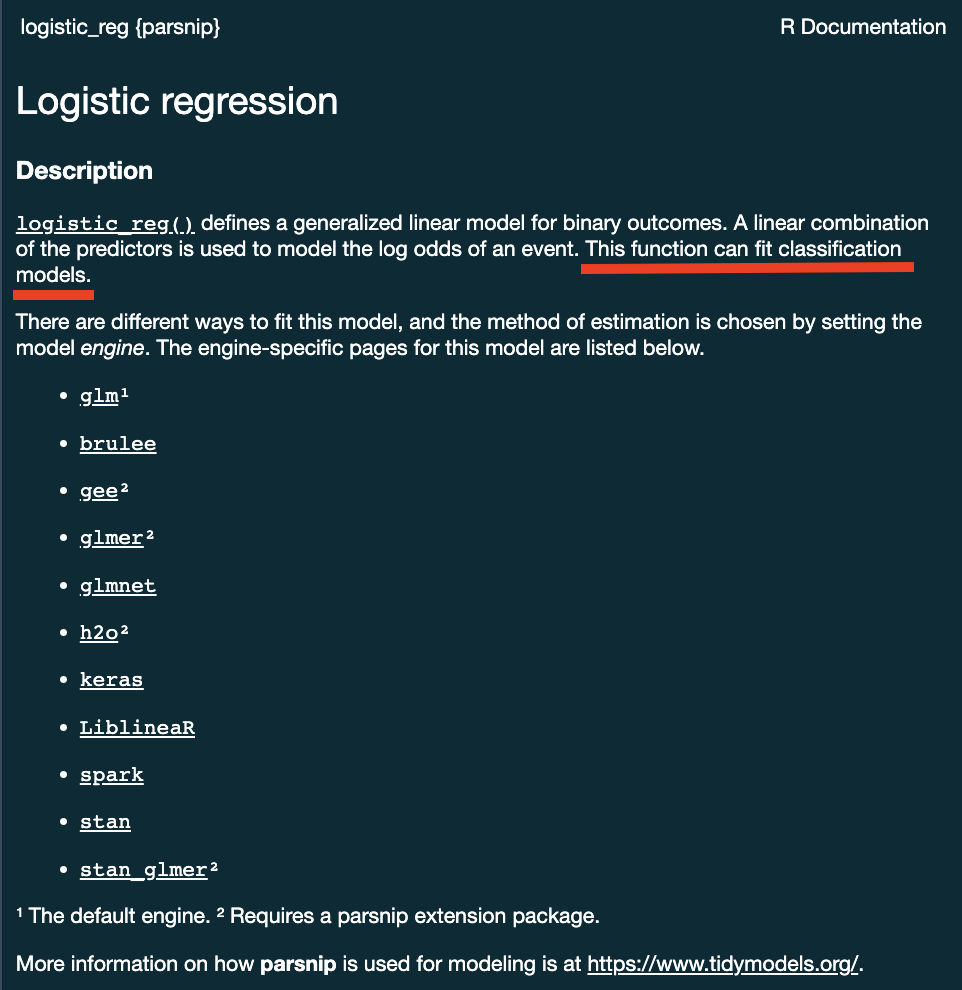
Next week we will discuss model types more thoroughly. For now, we will focus on two types:
- Logistic Regression
We chose these two because they are robust, simple models that fit our goal of predicting a binary condition/class (forested/not forested)
Specify a model: engine ![]()

Specify a model: engine ![]()
Specify a model: mode ![]()
Specify a model: mode ![]()
Some models have a limited set of modes …
. . .
Others require specification …
All available models are listed at https://www.tidymodels.org/find/parsnip/
To specify a model ![]()
- Choose a model
- Specify an engine
- Set the mode
Logistic regression
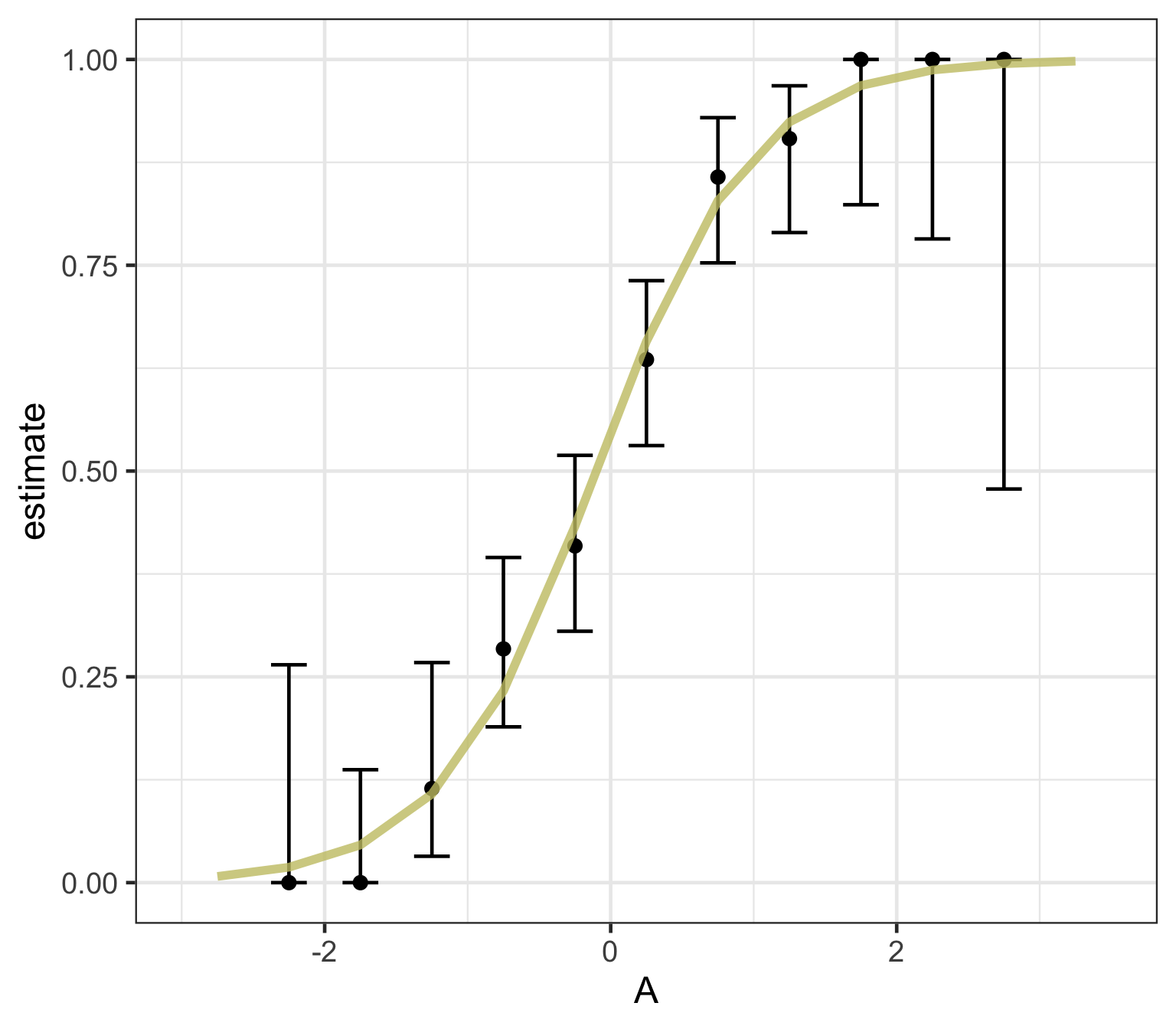
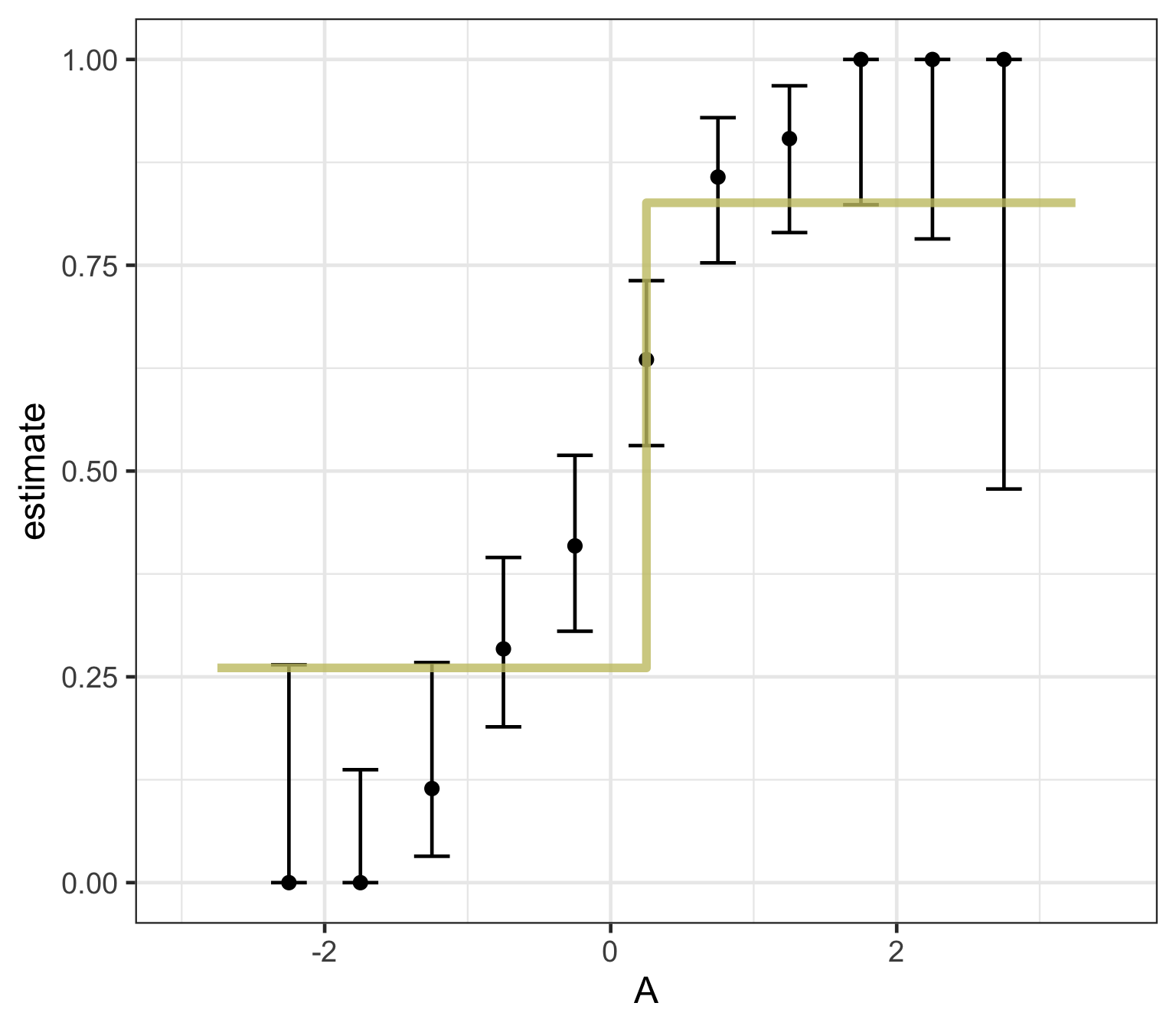
Logistic regression predicts probability—instead of a straight line, it gives an S-shaped curve that estimates how likely an outcome (e.g., is forested) is based on a predictor (e.g., rainfall and temperature).
The dots in the plot show the actual proportion of “successes” (e.g., is forested) within different bins of the predictor variable(s) (A).
The vertical error bars represent uncertainty—showing a range where the true probability might fall.
Logistic regression helps answer “how likely” questions—e.g., “How likely is someone to pass based on their study hours?” rather than just predicting a yes/no outcome.
Decision trees — structure & pruning
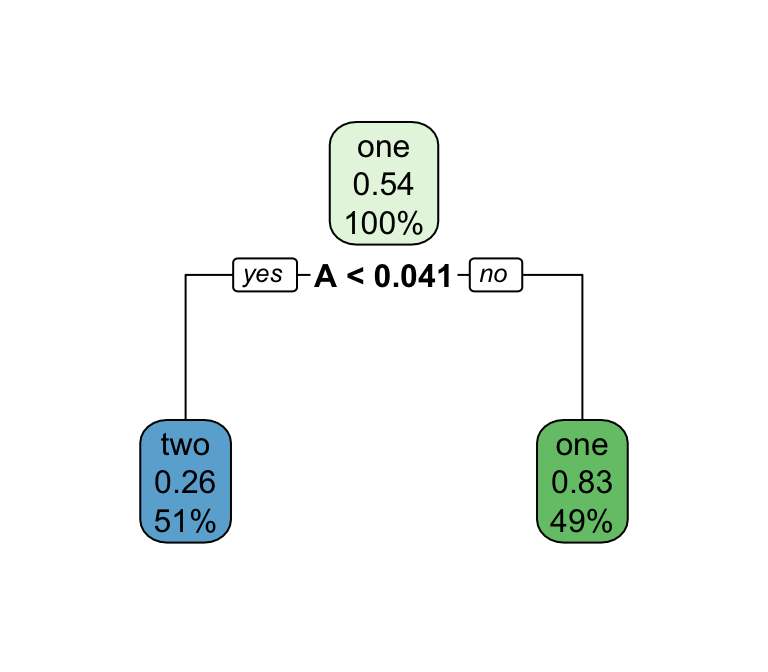
Series of splits or if/then statements based on predictors
First the tree grows until some condition is met (maximum depth, no more data)
Then the tree is pruned to reduce its complexity
Each terminal leaf predicts a class (or, for regression, a numeric value)
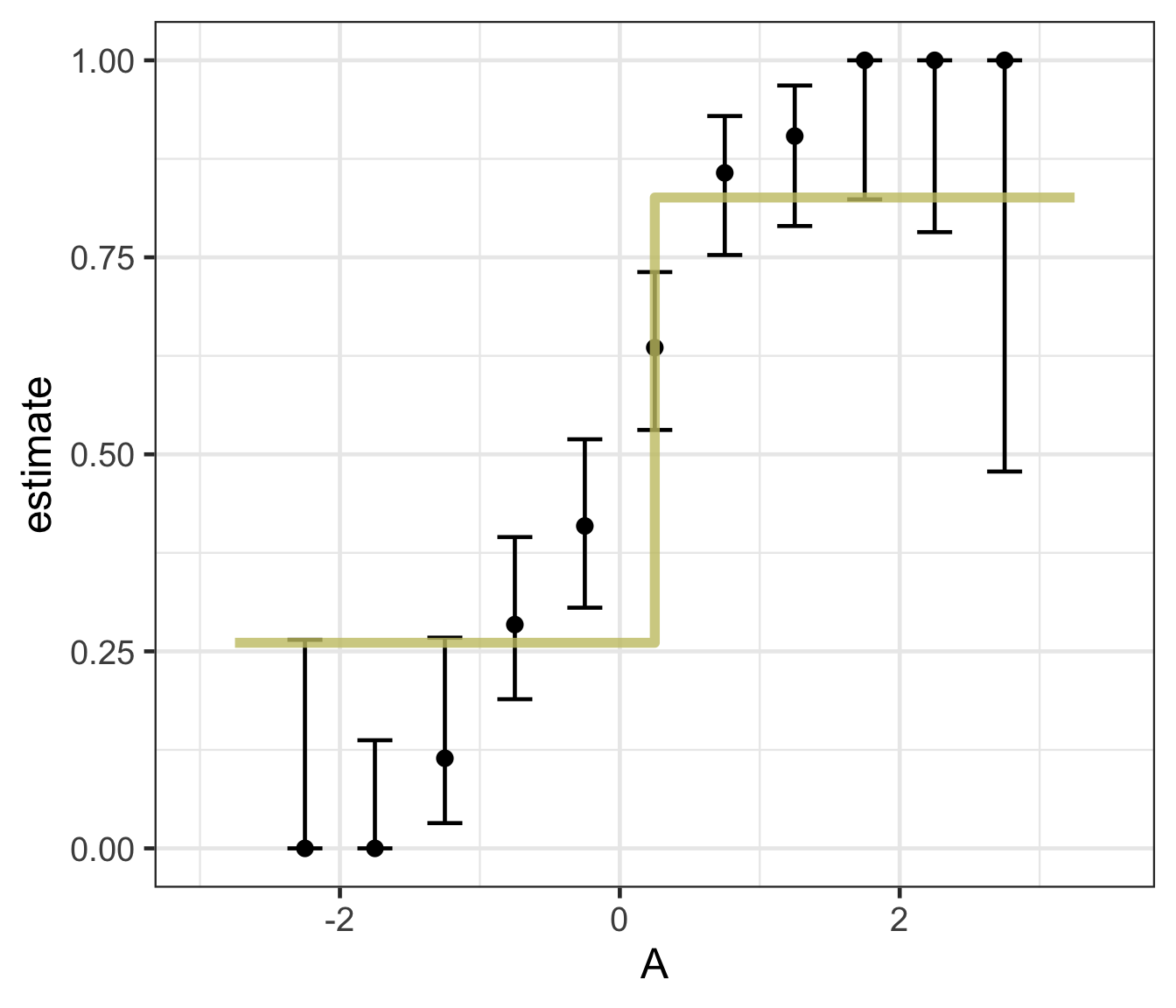
Decision trees — what predictions look like
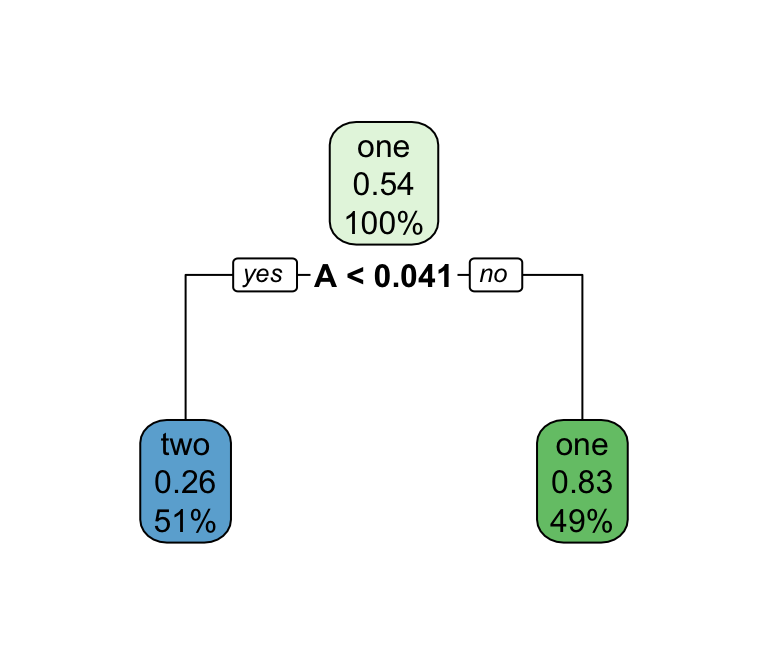
A tree’s decision boundary is stepwise — in contrast to the smooth S-curve of logistic regression.
What algorithm is best for estimating forested plots?
We can only really know by testing them … but we know the options!
Logistic regression
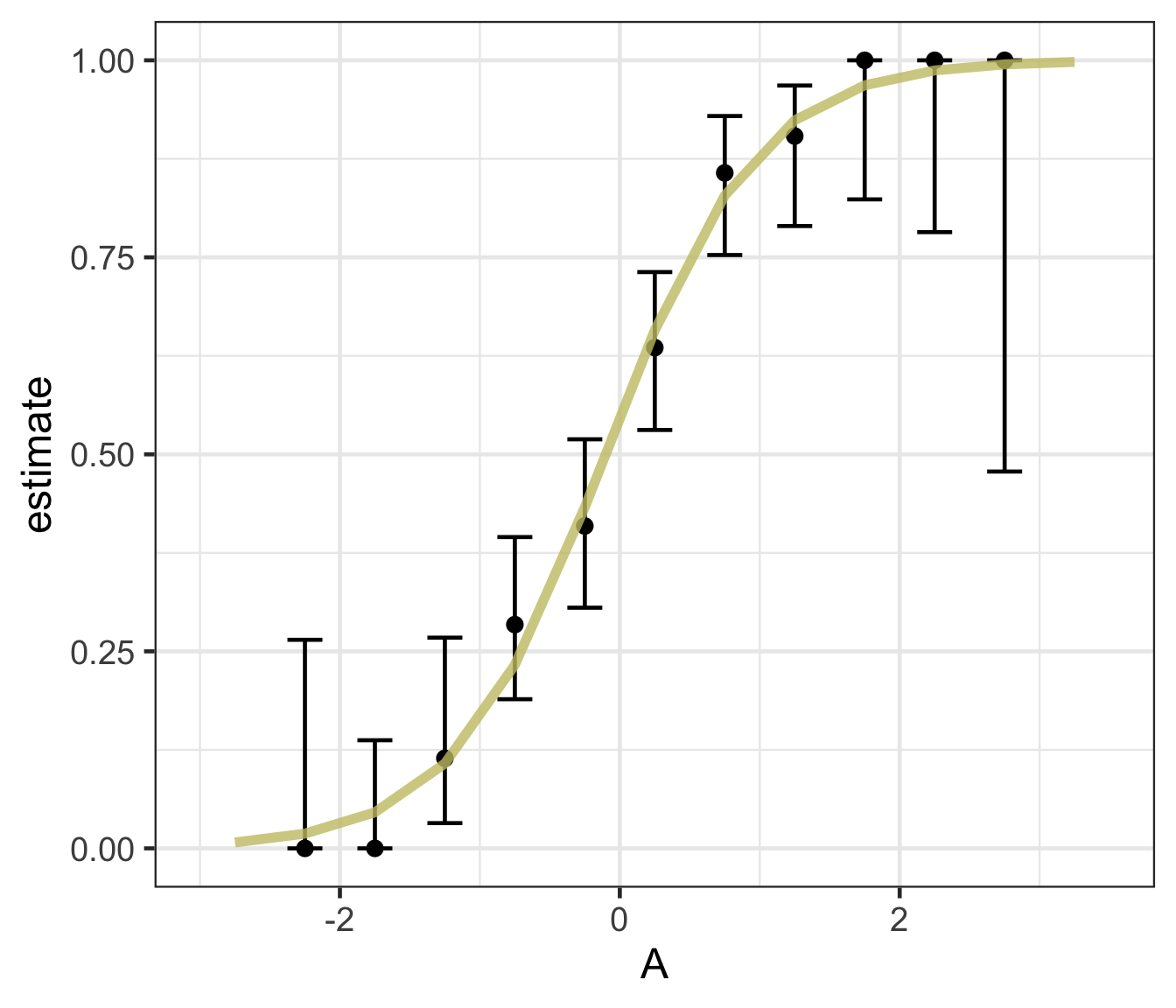
Decision trees
Why preprocess? ![]()

A raw formula (
forested ~ .) would send features to the model untouched.But many models care how their features look — different scales, skewed distributions, missing values, or categorical levels can bias the fit.
recipeslets us declare a preprocessing pipeline once, estimate its parameters from the training data, and apply it consistently to every new data set (folds, test set, future predictions).
Important
Preprocessing parameters (means, sds, imputed values, PCA loadings) are learned only on the training set — this prevents data leakage from test data into the fit.
A recipe for our running example ![]()
Back to forested. Before we fit any models, let’s declare the preprocessing pipeline we want every model in this deck to use — impute missing numeric values, dummy-encode the nominal predictors, and normalize everything numeric:
Note
We’ll reuse forested_recipe for every model we specify for the rest of today (decision tree, logistic regression, workflow set) — the point of a recipe is to define preprocessing once and reuse it everywhere. The same recipe carries forward into Wednesday’s lecture (VIP + spatial CV) and next week’s (more model families + tuning).
Component extracts:
While
tidymodelsprovides a standard interface to all models all base models have specific methods (remembersummary.lm? )To use these, you must extract the underlying object.
extract_fit_engine()extracts the underlying model objectextract_fit_parsnip()extracts the parsnip objectextract_recipe()extracts the recipe objectextract_preprocessor()extracts the preprocessor object… many more
Workflows — a container for your pipeline ![]()

The workflows package bundles a preprocessor (recipe or formula) and a model spec into a single object. Instead of managing prep → bake → fit by hand, you hand the workflow your training data and it does the bookkeeping on every resample.
The four-step pattern:
- Create a workflow (
workflow()— likeggplot()instantiates a canvas) - Add a preprocessor (
add_recipe()oradd_formula()) - Add a model (
add_model()) - Fit it (
fit()orfit_resamples())
Why bother?
✅ Preprocessing and modeling travel together — no forgetting to bake the test set ✅ Same skeleton for every model — swap in a new add_model() spec and go ✅ Works identically with a single fit(), resamples, or tuning
A model workflow ![]()
![]()
Instead of prep/bake/fit by hand, drop the recipe and the model into a workflow() and let it do the bookkeeping:
#> ══ Workflow [trained] ══════════════════════════════════════════════════════════
#> Preprocessor: Recipe
#> Model: decision_tree()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────
#> 3 Recipe Steps
#>
#> • step_impute_mean()
#> • step_dummy()
#> • step_normalize()
#>
#> ── Model ───────────────────────────────────────────────────────────────────────
#> n= 5685
#>
#> node), split, n, loss, yval, (yprob)
#> * denotes terminal node
#>
#> 1) root 5685 2571 Yes (0.54775726 0.45224274)
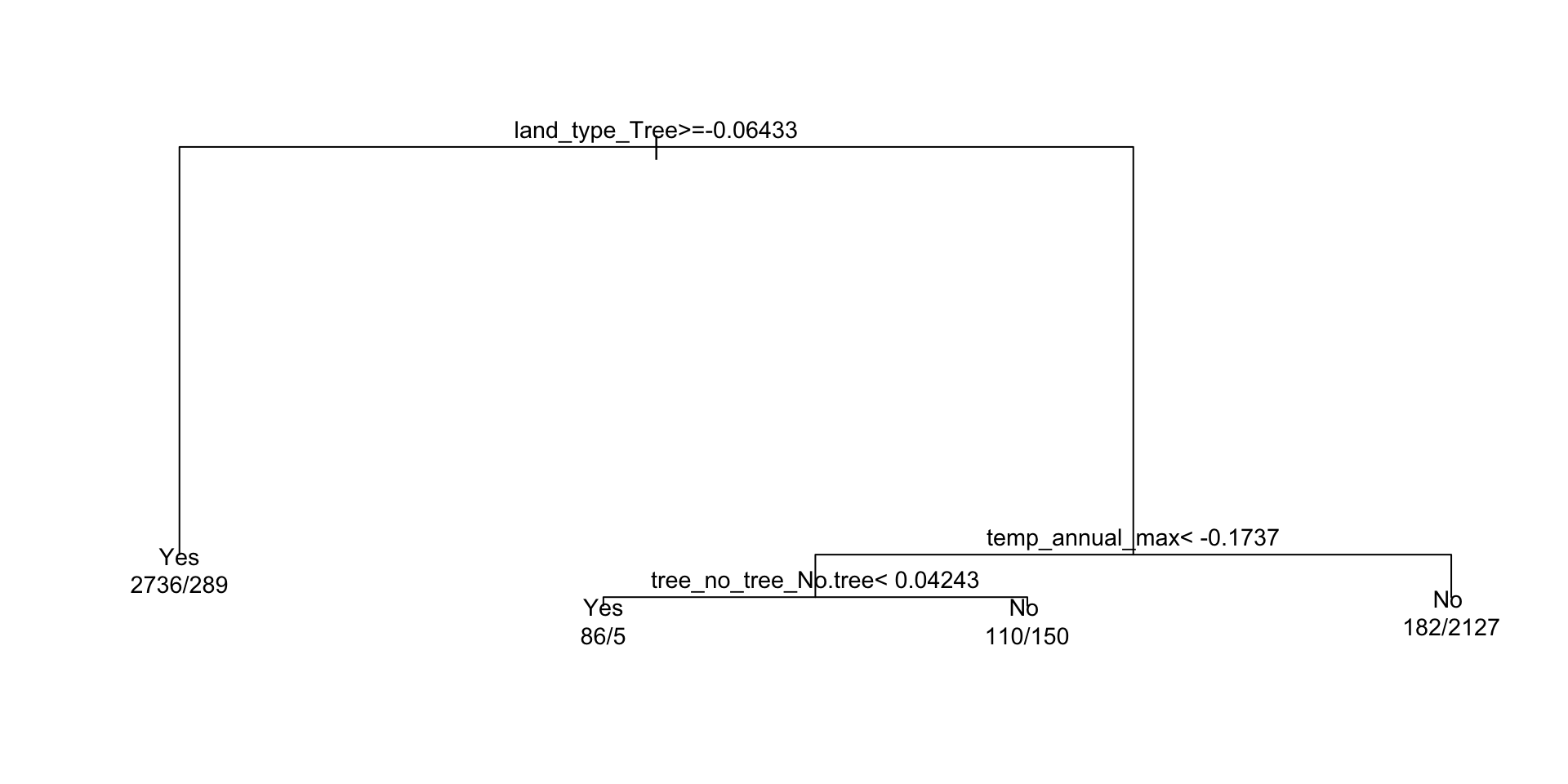
#> 2) land_type_Tree>=-0.06433113 3025 289 Yes (0.90446281 0.09553719) *
#> 3) land_type_Tree< -0.06433113 2660 378 No (0.14210526 0.85789474)
#> 6) temp_annual_max< -0.1737334 351 155 Yes (0.55840456 0.44159544)
#> 12) tree_no_tree_No.tree< 0.04242667 91 5 Yes (0.94505495 0.05494505) *
#> 13) tree_no_tree_No.tree>=0.04242667 260 110 No (0.42307692 0.57692308) *
#> 7) temp_annual_max>=-0.1737334 2309 182 No (0.07882200 0.92117800) *Tip
add_recipe() means the workflow carries your feature engineering pipeline and the model together — fit() automatically prep()/bake()s for every resample. (You can use add_formula() instead if you don’t need any preprocessing, but once you have a recipe there’s no reason to.)
Predict with your model ![]()
![]()
How do you apply your fitted workflow to the test set?
augment()on a workflow acceptsnew_data =and returns the test data with predictions appended.
#> # A tibble: 1,422 × 22
#> .pred_class .pred_Yes .pred_No forested year elevation eastness northness
#> <fct> <dbl> <dbl> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 Yes 0.904 0.0955 No 2005 164 -84 53
#> 2 Yes 0.904 0.0955 Yes 2005 806 47 -88
#> 3 No 0.423 0.577 Yes 2005 2240 -67 -74
#> 4 Yes 0.904 0.0955 Yes 2005 787 66 -74
#> 5 Yes 0.904 0.0955 Yes 2005 1330 99 7
#> 6 Yes 0.904 0.0955 Yes 2005 1423 46 88
#> 7 Yes 0.904 0.0955 Yes 2014 546 -92 -38
#> 8 Yes 0.904 0.0955 Yes 2014 1612 30 -95
#> 9 No 0.0788 0.921 No 2014 235 0 -100
#> 10 No 0.0788 0.921 No 2014 308 -70 -70
#> # ℹ 1,412 more rows
#> # ℹ 14 more variables: roughness <dbl>, tree_no_tree <fct>, dew_temp <dbl>,
#> # precip_annual <dbl>, temp_annual_mean <dbl>, temp_annual_min <dbl>,
#> # temp_annual_max <dbl>, temp_january_min <dbl>, vapor_min <dbl>,
#> # vapor_max <dbl>, canopy_cover <dbl>, lon <dbl>, lat <dbl>, land_type <fct>Evaluate your model ![]()

How do you evaluate the skill of your models?
We will learn more about model evaluation and tuning later in this unit, but for now we can blindly use the metrics() function defaults to get a sense of how our model is doing.
The default metrics for classification models are accuracy and kap (Cohen’s Kappa)
The default metrics for regression models are rmse, rsq (R²), and mae
tidymodels advantage! ![]()
- OK! while that was not too much work, it certainly wasn’t minimal.
Now let’s say you want to check if the logistic regression model performs better than the decision tree.
That sounds like a lot to repeat.
Fortunately, the
tidymodelsframework makes this a straightforward swap!
log_mod = logistic_reg() %>%
set_engine("glm") %>%
set_mode("classification")
log_wf <- workflow() %>%
add_recipe(forested_recipe) %>%
add_model(log_mod) %>%
fit(data = forested_train)
log_preds <- augment(log_wf, new_data = forested_test)
metrics(log_preds, truth = forested, estimate = .pred_class)
#> # A tibble: 2 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy binary 0.890
#> 2 kap binary 0.777Note
Note how little changed: same recipe, same workflow skeleton — only the model spec is different. That swap is the whole point of tidymodels.
Model mappings: ![]()
workflowsetsis a package that builds off ofpurrrand allows you to iterate over multiple models and/or multiple resamplesRemember how
map,map_*,map2, andwalk2functions allow lists to map to lists or vectors?workflow_setmaps a preprocessor (formula or recipe) to a set of models - each provided as alistobject.To start, we will create a
workflow_setobject (instead of aworkflow). The first argument is a list of preprocessor objects (formulas or recipes) and the second argument is a list of model objects.Both must be lists, by nature of the underlying
purrrcode.
Rapid comparison
With that single function, all models have been fit to the resamples and we can quickly compare the results both graphically and statistically:
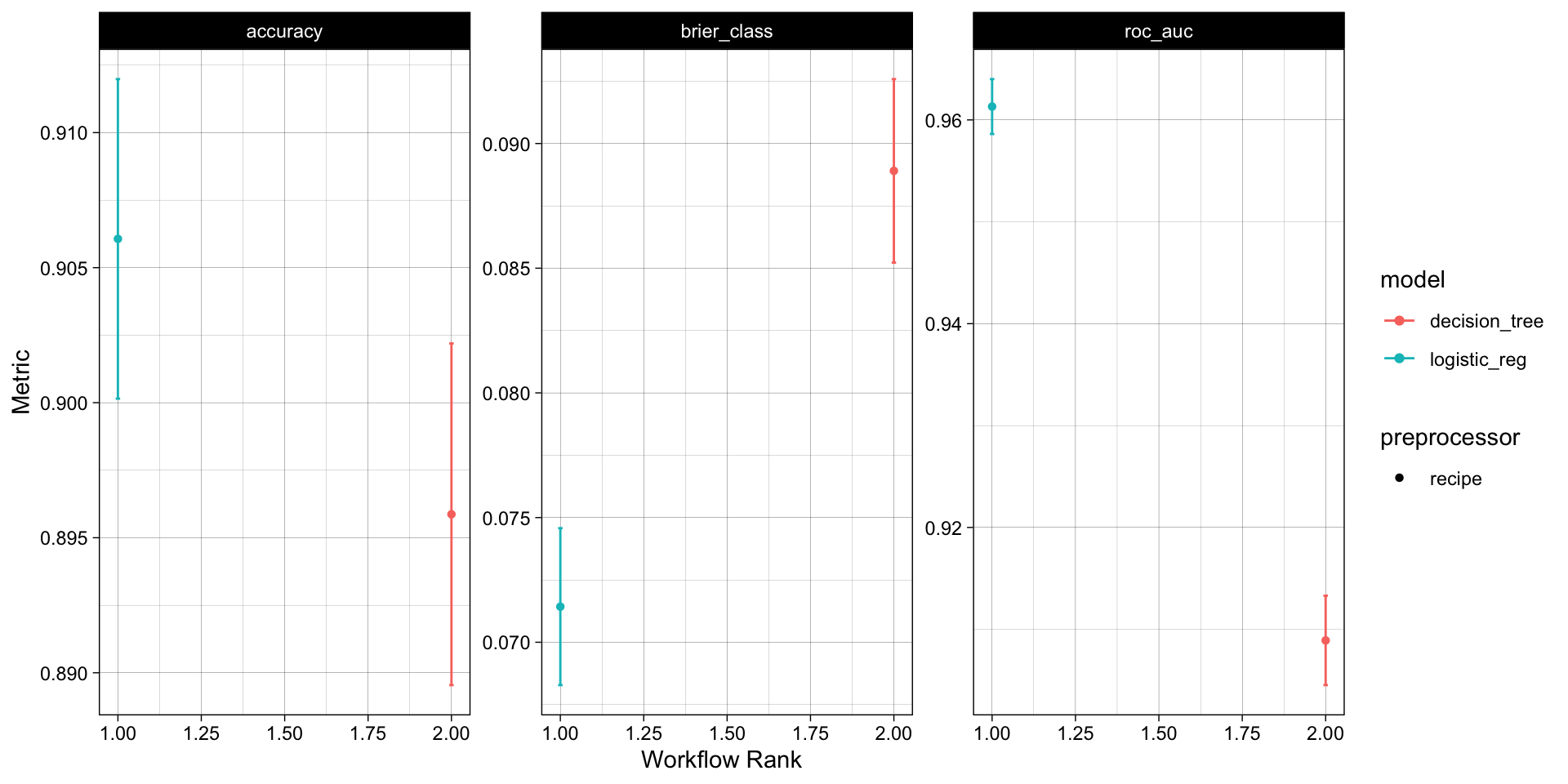
# Long list of results, ranked by accuracy
rank_results(wf_obj,
rank_metric = "accuracy",
select_best = TRUE)
#> # A tibble: 6 × 9
#> wflow_id .config .metric mean std_err n preprocessor model rank
#> <chr> <chr> <chr> <dbl> <dbl> <int> <chr> <chr> <int>
#> 1 recipe_logistic… pre0_m… accura… 0.906 0.00360 10 recipe logi… 1
#> 2 recipe_logistic… pre0_m… brier_… 0.0714 0.00191 10 recipe logi… 1
#> 3 recipe_logistic… pre0_m… roc_auc 0.961 0.00164 10 recipe logi… 1
#> 4 recipe_decision… pre0_m… accura… 0.896 0.00385 10 recipe deci… 2
#> 5 recipe_decision… pre0_m… brier_… 0.0889 0.00224 10 recipe deci… 2
#> 6 recipe_decision… pre0_m… roc_auc 0.909 0.00267 10 recipe deci… 2Overall, the logistic regression model appears to be the best model for this data set!
Note
Keep in mind: we compared these models out of the box, with no feature engineering, no hyperparameter tuning, and a single resampling scheme. Next week we’ll revisit this comparison once we can actually tune a model 👀
The whole game - status update
On Wednesday we’ll ask two things collect_metrics() can’t answer: which predictors did the model actually use (VIP) and is our 0.9-ish score honest (spatial cross-validation on autocorrelated data). Next week we’ll meet a bigger zoo of model families and learn to tune them.