# remotes::install_github("brunocarlin/tidy.outliers")Lecture 13
Unit 2: Review
Review Day!
Component 2: Working with Data
Build confidence in wrangling, visualizing, and analyzing data. This section covers importing and cleaning data sets, working with joins, and creating effective visualizations. You’ll also delve into study design, hypothesis testing, and statistical analyses spanning uni-variate, bivariate, and multivariate techniques.
Learning Outcomes
- Import, clean, and merge data sets from diverse sources using core
tidyversepackages. - Conduct hypothesis testing and interpret results.
- Create impactful visualizations to communicate findings.
We have covered a ton of material in unit 2.
Today
Tip
We will look at some public water quality data to examine the relationship between bicarbonate and magnesium/calcium along the Colorado River.
Motivation
The balance between bicarbonate and Mg+Ca in water determines hardness, alkalinity, and pH stability, with direct implications for ecosystem health, water treatment, and infrastructure maintenance. The sum of magnesium and calcium concentrations is a key factor in determining water hardness which can impact aquatic ecosystems, water treatment, and infrastructure due to scaling.
⬆️ bicarbonate + ⬆️ Ca/Mg: Indicates water passing through carbonate-rich geology (limestone/dolomite), leading to high hardness but good buffering capacity.
⬇️ bicarbonate + ⬆️ Ca/Mg: Suggests non-carbonate sources of Mg and Ca, potentially from industrial pollution or weathering of silicate rocks.
⬆️ bicarbonate + ⬇️ Ca/Mg: Could be influenced by inputs like agricultural runoff or natural dissolution of bicarbonates from atmospheric CO₂.
In this lab, we are interested in understanding the relationship between bicarbonate and magnesium/calcium in the Colorado River Basin using a set of gages that have been active over the last ~100 years
Namely, we are interested in:
- The trend of Bicarbonate over time
- The relationship of Bicarbonate to Magnesium + Calcium along the river
- The strength of a predictive model for Bicarbonate using the sum Magnesium Calcium
1. Data Import & Setup
Sometimes you need new libraries!
- We can install from CRAN with
install.packages("package_name") - We can install from GitHub with
remotes::install_github("username/package_name")
Start with our libraries
- Here we load the libraries we will use in this lab
tidyversefor data manipulationtidymodelsfor modelingdataRetrievalfor downloading dataflextablefor making nice tablesvisdatfor EDA
library(tidyverse)
#> ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.4 ✔ readr 2.1.5
#> ✔ forcats 1.0.0 ✔ stringr 1.5.1
#> ✔ ggplot2 3.5.1 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.4 ✔ tidyr 1.3.1
#> ✔ purrr 1.0.4
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(tidymodels)
#> ── Attaching packages ────────────────────────────────────── tidymodels 1.2.0 ──
#> ✔ broom 1.0.7 ✔ rsample 1.2.1
#> ✔ dials 1.4.0 ✔ tune 1.3.0
#> ✔ infer 1.0.7 ✔ workflows 1.2.0
#> ✔ modeldata 1.4.0 ✔ workflowsets 1.1.0
#> ✔ parsnip 1.3.0 ✔ yardstick 1.3.2
#> ✔ recipes 1.1.1
#> ── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
#> ✖ scales::discard() masks purrr::discard()
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ recipes::fixed() masks stringr::fixed()
#> ✖ dplyr::lag() masks stats::lag()
#> ✖ yardstick::spec() masks readr::spec()
#> ✖ recipes::step() masks stats::step()
#> • Learn how to get started at https://www.tidymodels.org/start/
library(dataRetrieval)
library(flextable)
#>
#> Attaching package: 'flextable'
#>
#> The following object is masked from 'package:purrr':
#>
#> compose
library(visdat) We can predefine our sites of interest for expediency. We do this by creating a data frame with the SiteID and SiteName
atomicvectors.We can also predefine the variables we are interested in.
sites <- tibble(SiteID = c("USGS-09069000", "USGS-09085000", "USGS-09095500",
"USGS-09152500", "USGS-09180000", "USGS-09380000"),
SiteName = c("Eagle", "Roaring Fork", "Colorado 3",
"Gunnison", "Dolores", "Colorado 5"))
vars <- c('Magnesium', 'Calcium', 'Bicarbonate')Explore the Sites
## Access
site.info <- whatWQPsites(siteid = sites$SiteID)
#> GET:https://www.waterqualitydata.us/data/Station/search?siteid=USGS-09069000%3BUSGS-09085000%3BUSGS-09095500%3BUSGS-09152500%3BUSGS-09180000%3BUSGS-09380000&mimeType=csv&count=no
names(site.info)
#> [1] "OrganizationIdentifier"
#> [2] "OrganizationFormalName"
#> [3] "MonitoringLocationIdentifier"
#> [4] "MonitoringLocationName"
#> [5] "MonitoringLocationTypeName"
#> [6] "MonitoringLocationDescriptionText"
#> [7] "HUCEightDigitCode"
#> [8] "DrainageAreaMeasure.MeasureValue"
#> [9] "DrainageAreaMeasure.MeasureUnitCode"
#> [10] "ContributingDrainageAreaMeasure.MeasureValue"
#> [11] "ContributingDrainageAreaMeasure.MeasureUnitCode"
#> [12] "LatitudeMeasure"
#> [13] "LongitudeMeasure"
#> [14] "SourceMapScaleNumeric"
#> [15] "HorizontalAccuracyMeasure.MeasureValue"
#> [16] "HorizontalAccuracyMeasure.MeasureUnitCode"
#> [17] "HorizontalCollectionMethodName"
#> [18] "HorizontalCoordinateReferenceSystemDatumName"
#> [19] "VerticalMeasure.MeasureValue"
#> [20] "VerticalMeasure.MeasureUnitCode"
#> [21] "VerticalAccuracyMeasure.MeasureValue"
#> [22] "VerticalAccuracyMeasure.MeasureUnitCode"
#> [23] "VerticalCollectionMethodName"
#> [24] "VerticalCoordinateReferenceSystemDatumName"
#> [25] "CountryCode"
#> [26] "StateCode"
#> [27] "CountyCode"
#> [28] "AquiferName"
#> [29] "LocalAqfrName"
#> [30] "FormationTypeText"
#> [31] "AquiferTypeName"
#> [32] "ConstructionDateText"
#> [33] "WellDepthMeasure.MeasureValue"
#> [34] "WellDepthMeasure.MeasureUnitCode"
#> [35] "WellHoleDepthMeasure.MeasureValue"
#> [36] "WellHoleDepthMeasure.MeasureUnitCode"
#> [37] "ProviderName"
## Make a map!
ggplot(site.info, aes(x = LongitudeMeasure, y = LatitudeMeasure)) +
borders("state") +
geom_point() +
theme_linedraw()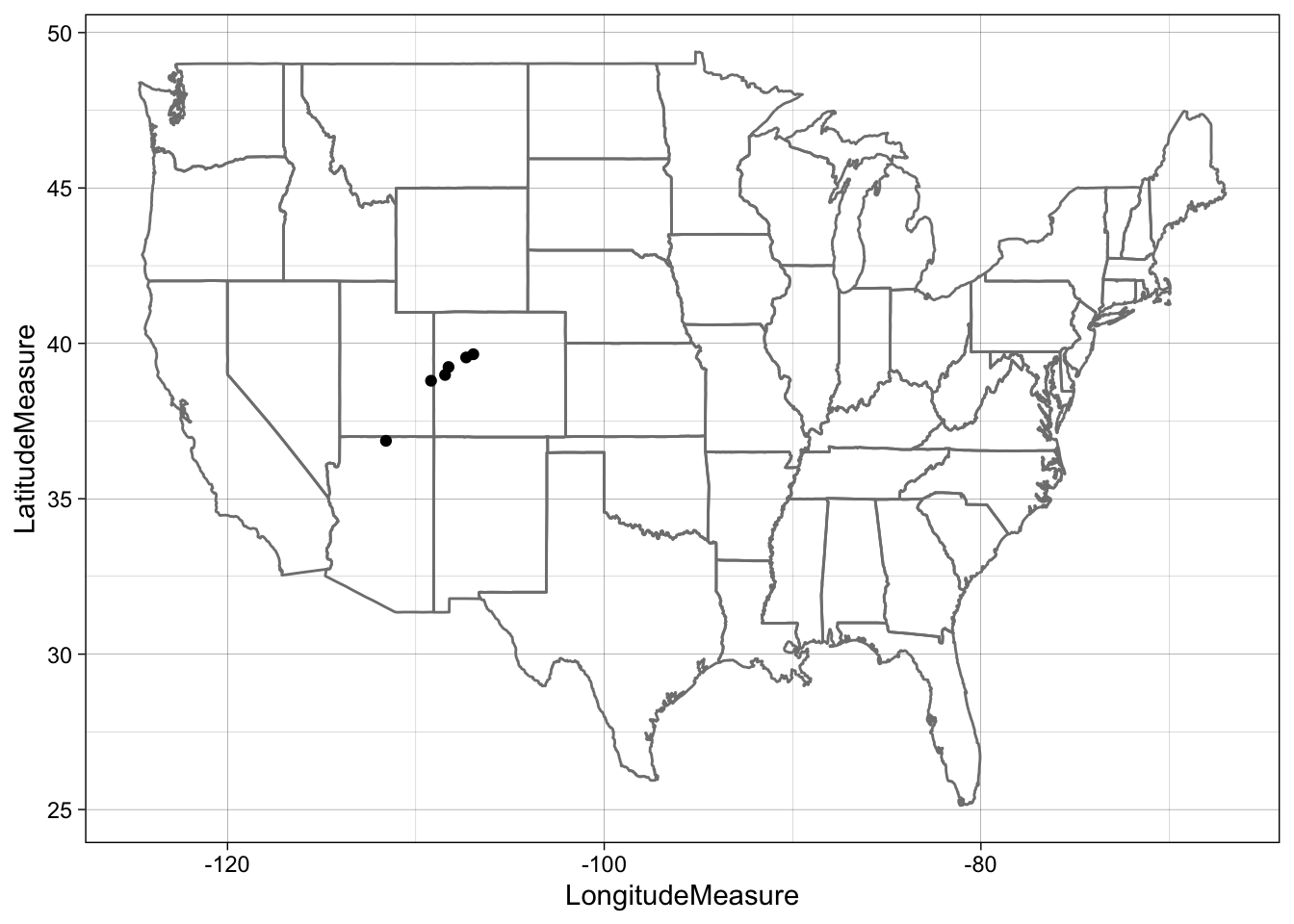
Data I/O
- We can use the
dataRetrievalpackage to download data from the USGS NWIS database. - This provides API access to the USGS NWIS database opposed to reading from a file.
# Data Access
nwis_wqp <- readWQPqw(siteNumbers = sites$SiteID, parameterCd = vars) |>
select(date = ActivityStartDate,
parameter = CharacteristicName,
SiteID = MonitoringLocationIdentifier,
value = ResultMeasureValue,
units = ResultMeasure.MeasureUnitCode,
media = ActivityMediaName) |>
filter(media=='Water') |>
left_join(sites, by = "SiteID") |>
select(contains('Site'), date, units, parameter, value)
#> GET:https://www.waterqualitydata.us/data/Result/search?siteid=USGS-09069000%3BUSGS-09085000%3BUSGS-09095500%3BUSGS-09152500%3BUSGS-09180000%3BUSGS-09380000&count=no&characteristicName=Magnesium%3BCalcium%3BBicarbonate&mimeType=csv
#> Waiting 2s for throttling delay ■■■■■■■■■■■■■■■
#> Waiting 2s for throttling delay ■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
#> NEWS: Data does not include USGS data newer than March 11, 2024. More details:
#> https://doi-usgs.github.io/dataRetrieval/articles/Status.html
## EDA!
##
glimpse(nwis_wqp)
#> Rows: 16,795
#> Columns: 6
#> $ SiteID <chr> "USGS-09180000", "USGS-09180000", "USGS-09180000", "USGS-091…
#> $ SiteName <chr> "Dolores", "Dolores", "Dolores", "Dolores", "Dolores", "Dolo…
#> $ date <date> 1968-11-18, 1968-11-18, 1968-11-18, 1969-01-29, 1969-01-29,…
#> $ units <chr> "mg/l", "mg/l", "mg/l", "mg/l", "mg/l", "mg/l", "mg/l", "mg/…
#> $ parameter <chr> "Bicarbonate", "Magnesium", "Calcium", "Calcium", "Magnesium…
#> $ value <dbl> 148, 72, 132, 98, 55, 168, 124, 43, 10, 17, 78, 112, 76, 27,…
vis_dat(nwis_wqp)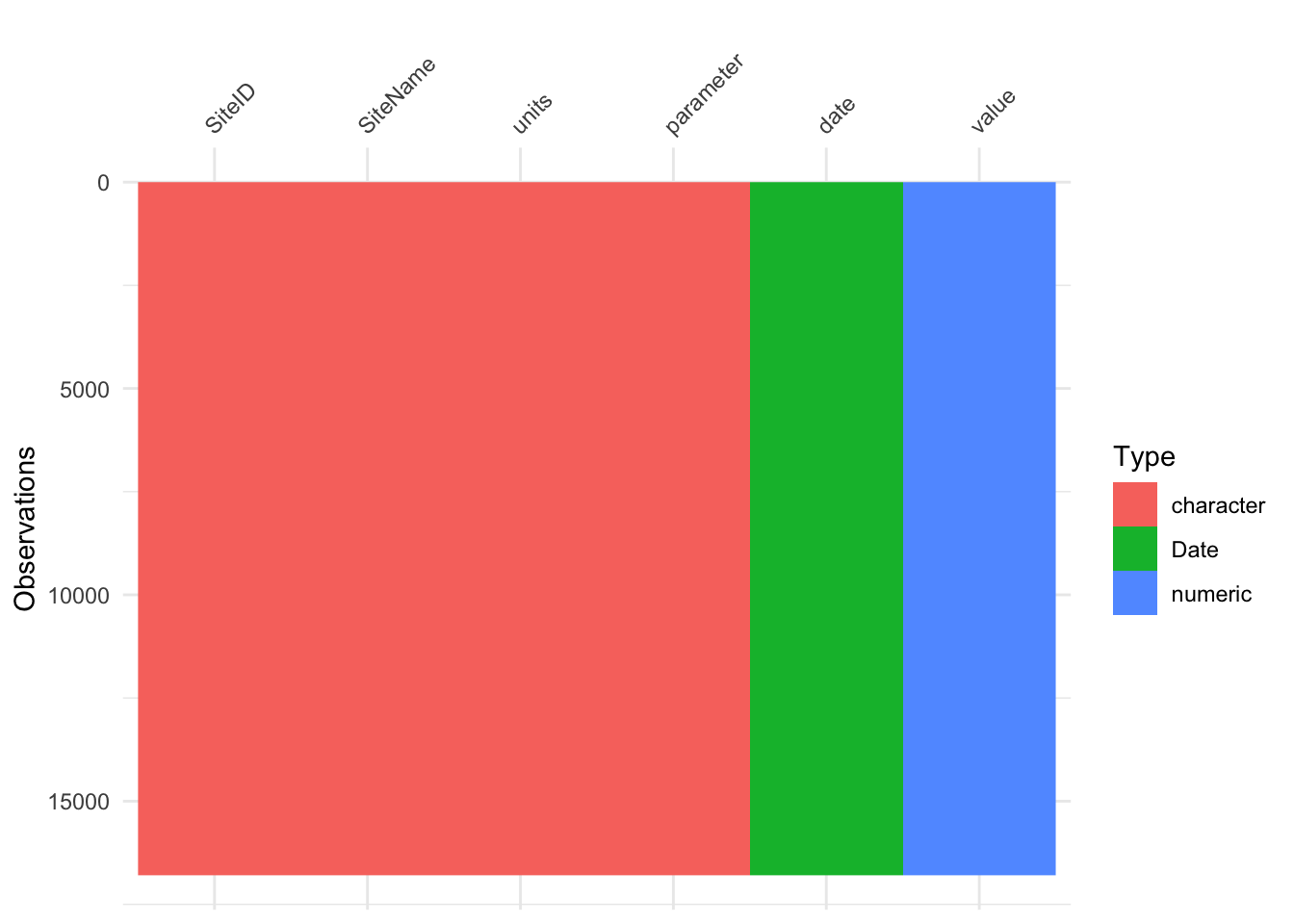
range(nwis_wqp$date)
#> [1] "1926-01-11" "2024-02-28"Data Tidying & EDA
# Compute Annual means
conc.annual <- nwis_wqp |>
mutate(year = year(date)) |>
group_by(SiteID, SiteName, year, parameter) |>
summarise(annual_conc = mean(value, na.rm = TRUE)) |>
ungroup()
#> `summarise()` has grouped output by 'SiteID', 'SiteName', 'year'. You can
#> override using the `.groups` argument.
# Visualize the data
ggpubr::ggscatter(conc.annual,
x = "year",
y = "annual_conc",
color = "parameter") +
facet_wrap(~SiteName)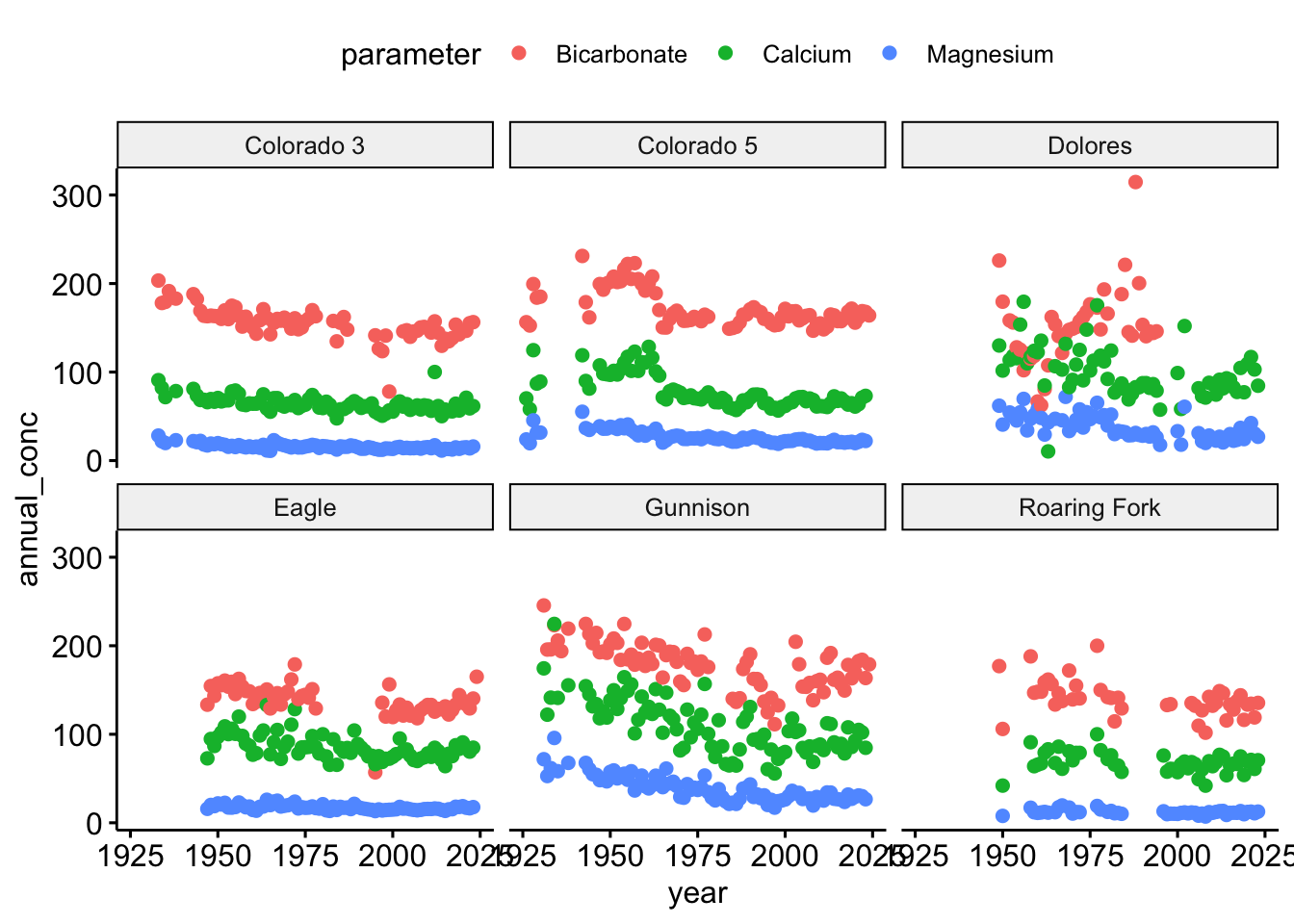
Modeling
# Long to wide, adding data
conc.wide = conc.annual |>
pivot_wider(names_from = parameter,
values_from = annual_conc) |>
mutate(MgCa = Magnesium + Calcium)
# Model Assumptions
shapiro.test(log(conc.wide$Calcium))
#>
#> Shapiro-Wilk normality test
#>
#> data: log(conc.wide$Calcium)
#> W = 0.93671, p-value = 7.274e-13
map(conc.wide[, c('Calcium', "MgCa")], shapiro.test)
#> $Calcium
#>
#> Shapiro-Wilk normality test
#>
#> data: .x[[i]]
#> W = 0.89805, p-value < 2.2e-16
#>
#>
#> $MgCa
#>
#> Shapiro-Wilk normality test
#>
#> data: .x[[i]]
#> W = 0.87253, p-value < 2.2e-16
ggplot(conc.wide, aes(x = Bicarbonate, y =MgCa)) +
geom_point() +
facet_wrap(~SiteName) +
geom_smooth(method = "lm")
#> `geom_smooth()` using formula = 'y ~ x'
#> Warning: Removed 86 rows containing non-finite outside the scale range
#> (`stat_smooth()`).
#> Warning: Removed 86 rows containing missing values or values outside the scale range
#> (`geom_point()`).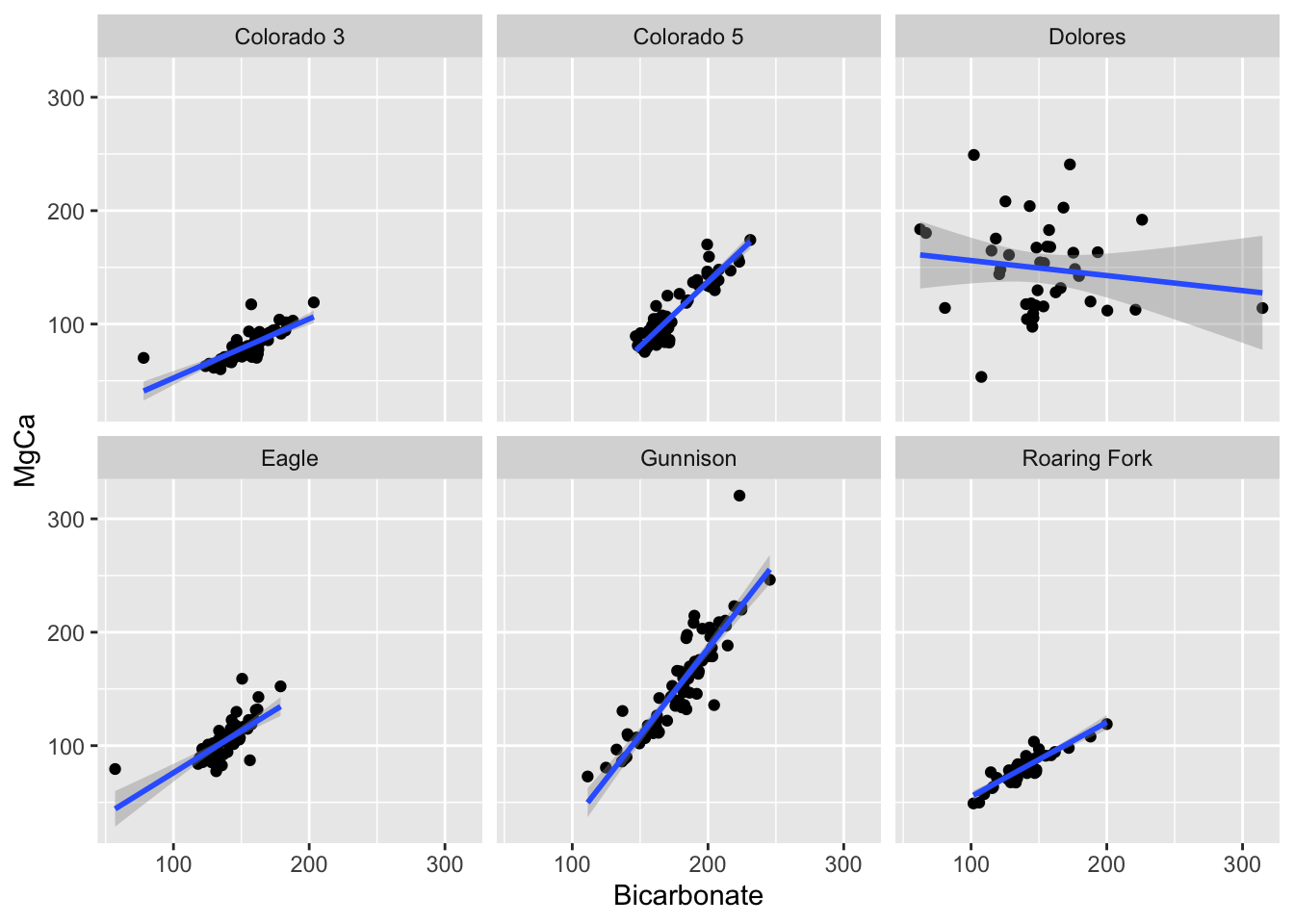
Feature Engineering
# Help
library(tidy.outliers)
# Feature Engineering
rec = conc.wide |>
drop_na() |>
recipe() |>
step_filter(SiteName != "Dolares") |>
step_sqrt("Bicarbonate", "MgCa") |>
prep(conc.wide)
norm_data = bake(rec, new_data = NULL)
# EDAModeling
# Bicarbonate Trends over the years# Bicarbonate vs. Magnesium + Calcium# Predictive modelSummary
What did we find? Did this align with our expectations? Did the process we just go through make sense? Did any of the skills seem alien?
Assignment
As we have reached the half way point of this course, take a moment to reflect on your journey so far. Please respond to each of the following prompts in a few sentences. The questions are guiding but not all need to be answered directly and deviations are welcome
1. Unit 1: Think back to the beginning—how comfortable were you with setting up and using R, RStudio, Git, and GitHub? Do you now feel more confident in managing your computational environment and organizing your data? What aspects still feel challenging or unclear? Do you feel that the skills learned are transitioning into other areas of your “computational life”?
2. Unit 2 : As we wrap up our primary unit on data wrangling, visualization, and analysis, how do you feel about your ability to import, clean, and work with data? Are there specific techniques (joins, visualizations, statistical methods, nests/groups) that you feel you’ve improved on? Thinking back 8 weeks, are you proud of the progress you’ve made or feeling lost? What areas do you want to focus on strengthening as we continue?
3. Looking Ahead:: Are you making the progress you hoped for? If not, what barriers are you facing, and what steps could help you overcome them? If yes, what strategies have been working for you? What are your goals for the remainder of the course and how can the teaching team best support you in reaching them?
4. Modes of Learning: How do you feel about the methods in which content is shared? Have lectures been useful? Labs? Office hours? Daily Exercises? What would you like to see continue, and what would you like us to consider changing to help your growth?
We know the learning curve with coding is STEEP!, but if you feel you are hanging on, I promise you are doing well.
Please be honest with yourself (and with us) in this reflection—there are no wrong answers! This is an opportunity to take stock of your growth and identify where you’d like to go next, and, for us to adopt to how we support you best.