Week 6
Machine Learning Part 2
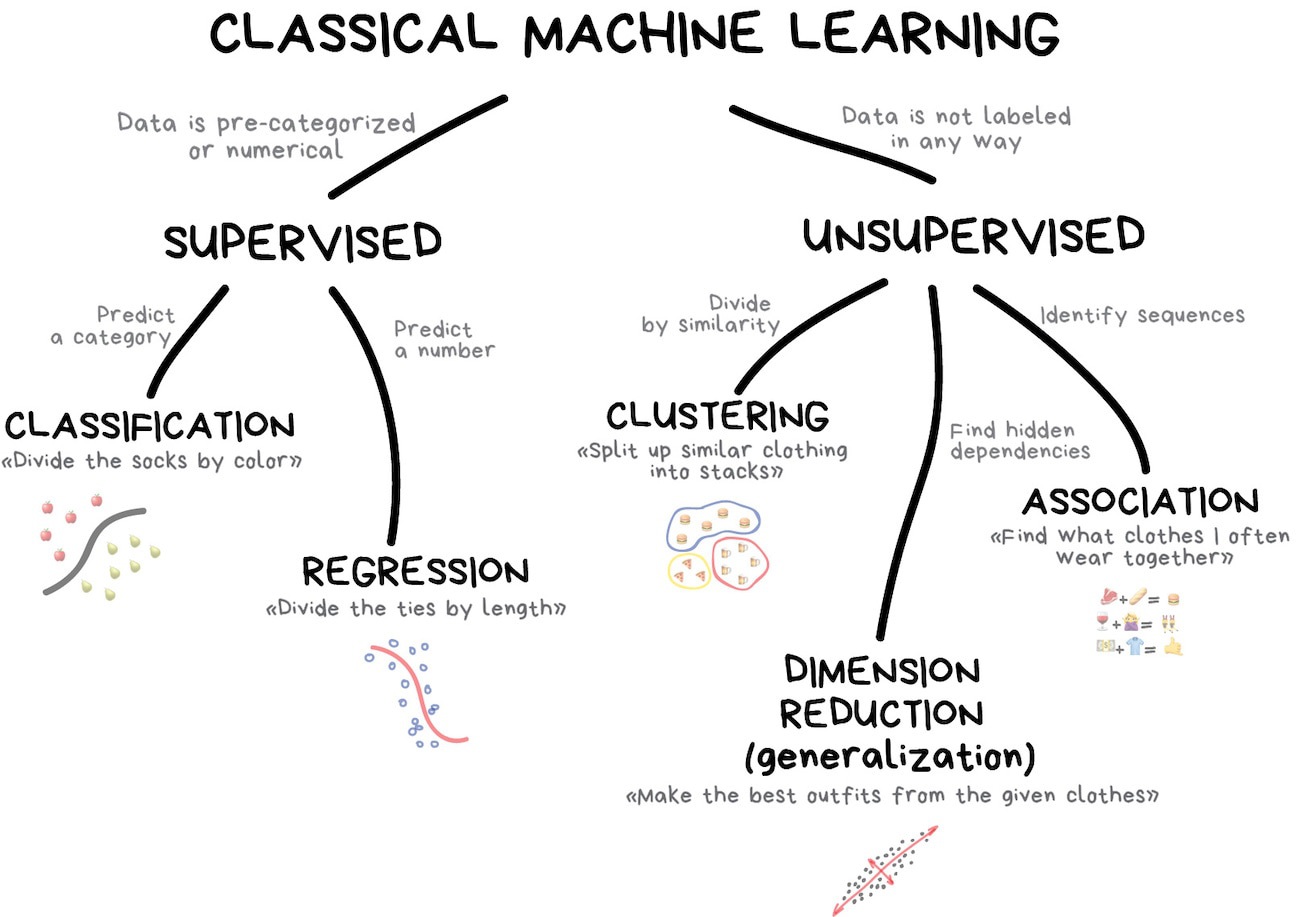
Introduction 
Machine learning (ML) is widely used in environmental science for tasks such as land cover classification, climate modeling, and forested distribution prediction. This lecture explores five common ML model specifications the tidymodels framework in R, applied to the forested dataset.
Linear Regression
Logistic Regression
Trees
- Decision Tree
- Random Forest
- Boost
- Decision Tree
Support Vector Machines
Neural Nets
Classification vs. Prediction
Most machine learning applications in environmental science serve different purposes (modes):
Classification Models → Categorize features into predefined classes.
Prediction Models → Forecast numerical environmental variables based on past trends.
Classification Models
Goal: Categorize phenomena into discrete classes.
Examples:
✅ Land Cover Classification (Forest, Urban, Water, Agriculture)
✅ Flood Risk Assessment (High, Medium, Low)
✅ Drought Severity Levels (No Drought, Moderate, Severe)
✅ Wildfire Prediction (Fire vs. No Fire)
✅ forested Identification (Bird forested, Plant Types)
Common Algorithms:
- Decision Trees
- Random Forest
- Support Vector Machines (SVM)
- Neural Networks (for remote sensing & image analysis)
- K-Nearest Neighbors (KNN)
Prediction Models
Goal: Estimate continuous environmental variables.
Examples:
📈 Streamflow Forecasting (Predict river discharge over time)
🌡️ Temperature Projections (Future temperature changes under climate scenarios)
☔ Precipitation Forecasting (Rainfall estimates for flood preparedness)
📊 Air Quality Index Prediction (Forecast pollution levels)
Common Algorithms:
- Linear & Multiple Regression
- Random Forest Regression
- Long Short-Term Memory (LSTM) Neural Networks (for time series forecasting)
Choosing the Right Model
Use classification if: You need to categorize environmental states (e.g., classifying land use changes).
Use prediction if: You need to forecast environmental conditions (e.g., predicting flood levels)
Use hybrid approaches if: You need to classify and predict (e.g., classifying drought severity and then predicting future water availability).
Model Selection Considerations
Choosing an ML algorithm (model) depends on:
Dataset Size: e.g. Large datasets benefit from ensemble methods like Random Forest and XGBoost.
Feature Complexity: e.g. SVM works well for high-dimensional data.
Interpretability Needs: e.g. Decision trees and LASSO regression provide intuitive insights.
Computation Constraints: e.g. GLM and Decision Trees are efficient compared to XGBoost.
Data: Variance, linearity, diminsionality
Load Required Libraries 

library(tidyverse)
library(tidymodels)
library(forested)
library(flextable)Data Preparation 
We will use the forested dataset for classification tasks. The dataset contains information about penguin forested, body measurements, and other environmental factors.
set.seed(123)
forested_split <- initial_split(forested, strata = tree_no_tree)
forested_train <- training(forested_split)
forested_test <- testing(forested_split)
forested_folds <- vfold_cv(forested_train, v = 10)
# Feature Engineering: Classification
forested_recipe <- recipe(forested ~ ., data = forested_train) |>
step_dummy(all_nominal_predictors()) |>
step_normalize(all_numeric_predictors()) |>
step_impute_mean(all_numeric_predictors())Machine Learning Specifications in tidymodels
Unified Interface for ML Models 
- The
parsnippackage is a part of thetidymodelsframework - It provides a consistent interface for specifying models through specifications
- The combination of a specification, mode, and engine is called a model
- Lets look at the parsnip documentation!
What are hyperparameters?
- Hyperparameters are settings that control the learning process of a model.
- They are set before training and affect the model’s performance.
- Hyperparameters can be tuned to optimize the model’s predictive power.
- More on model tuning next week!
1. Linear Regression
Linear regression is a fundamental statistical method used for modeling the relationship between a dependent variable and one or more independent variables. It is widely used in environmental science for tasks such as predicting forested distribution, estimating climate variables, and modeling ecosystem dynamics.
Components of Linear Regression
- Dependent Variable (Y): The variable to be predicted.
- Independent Variables (X): Features that influence the dependent variable.
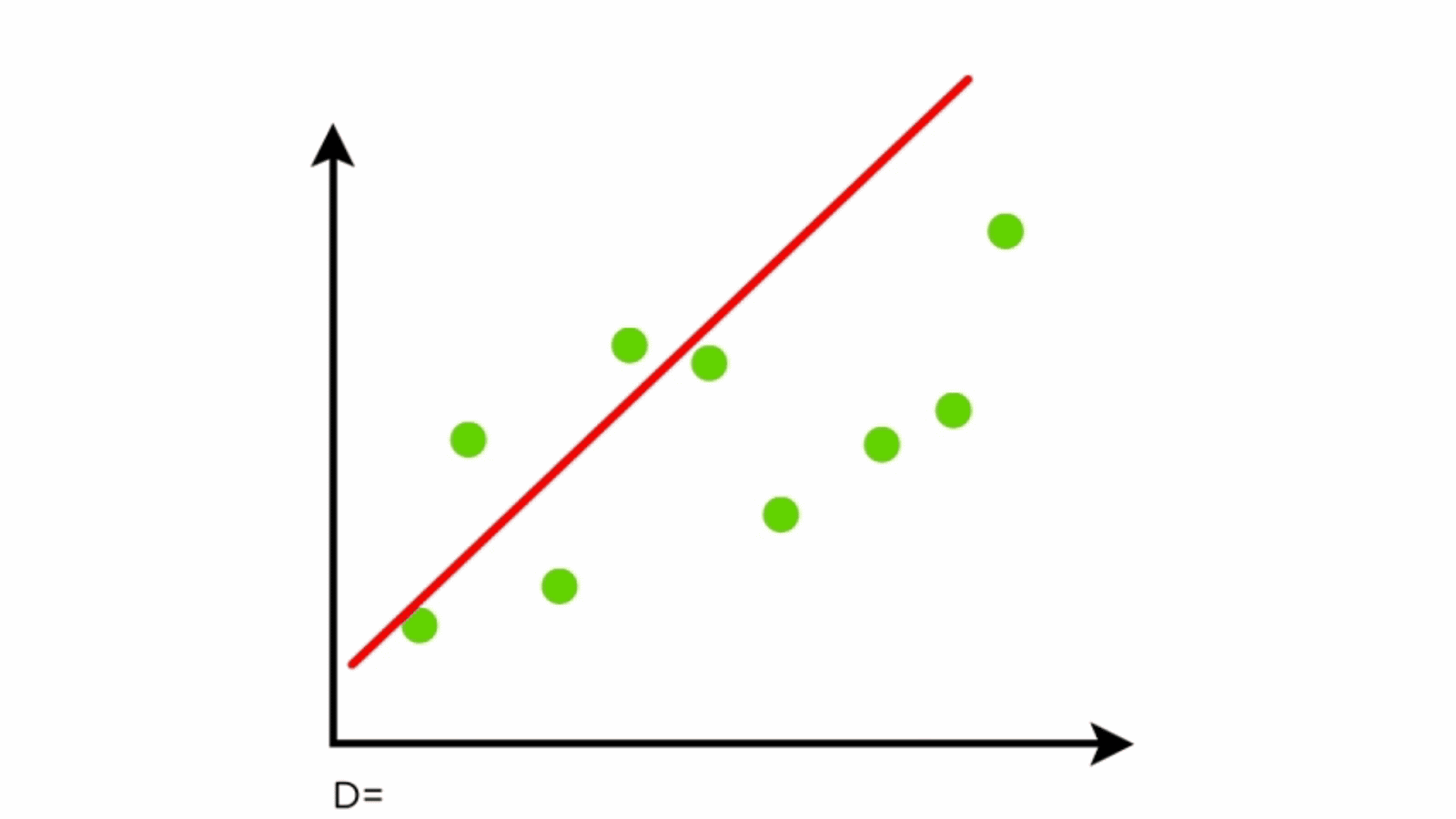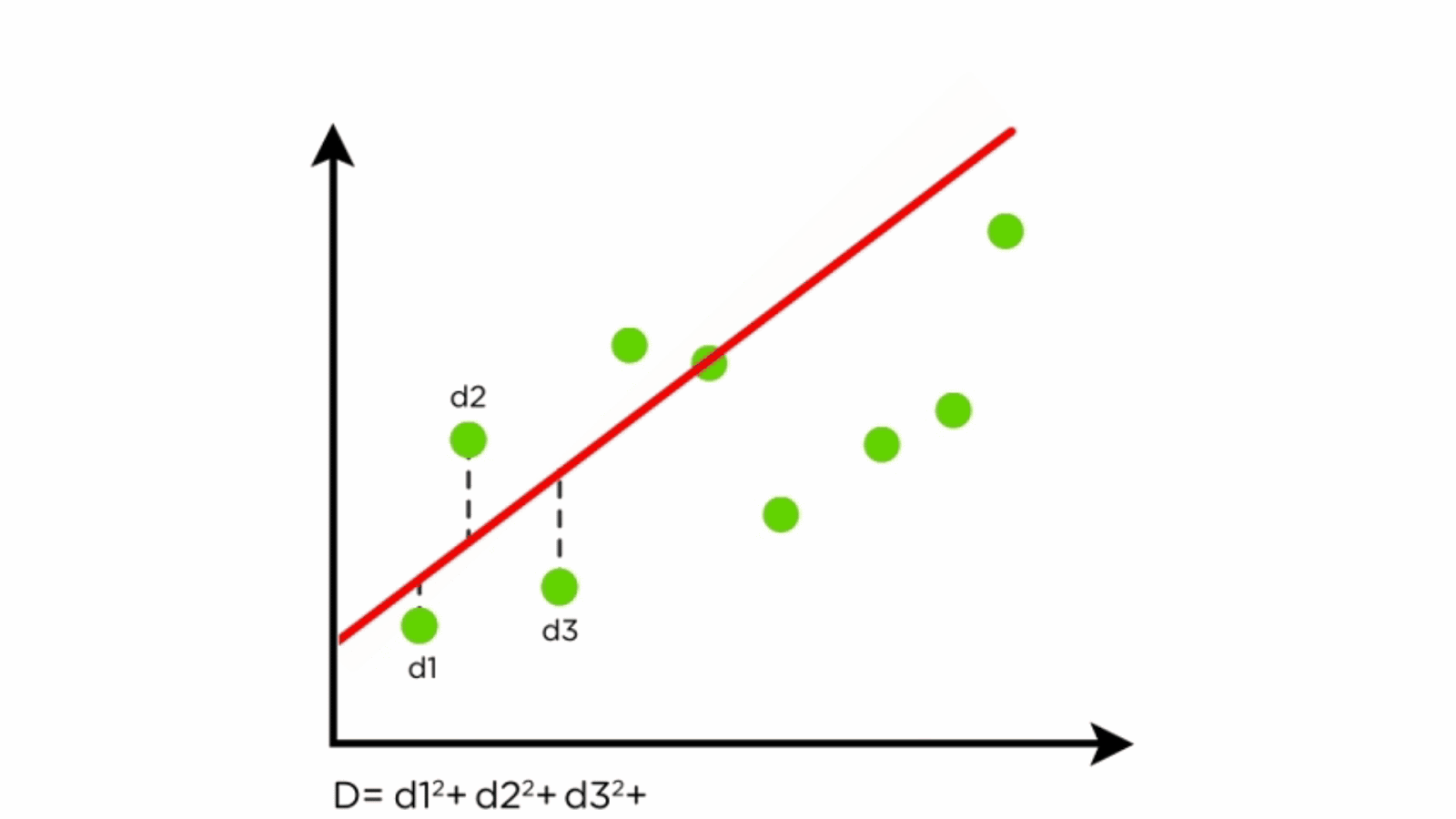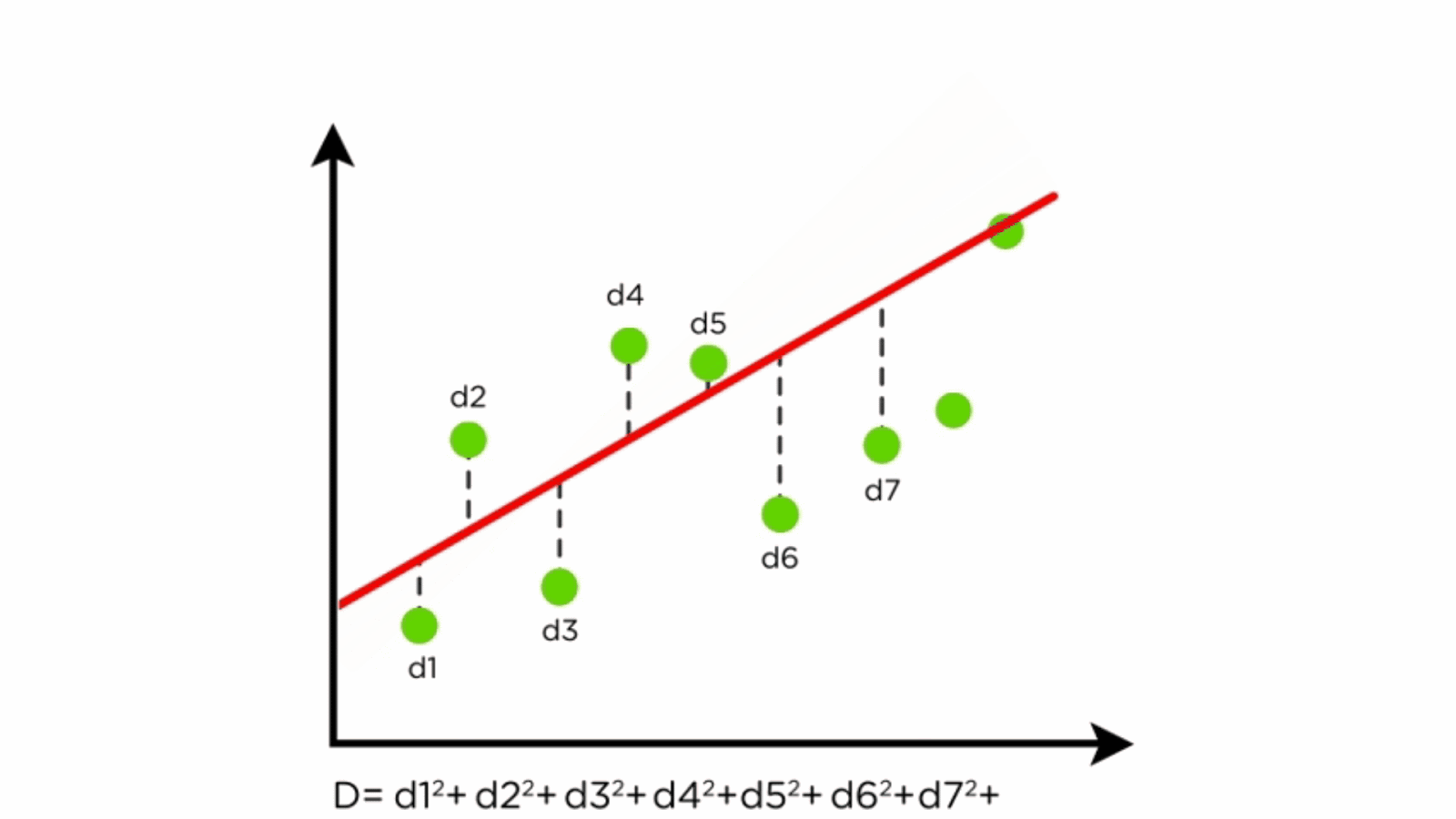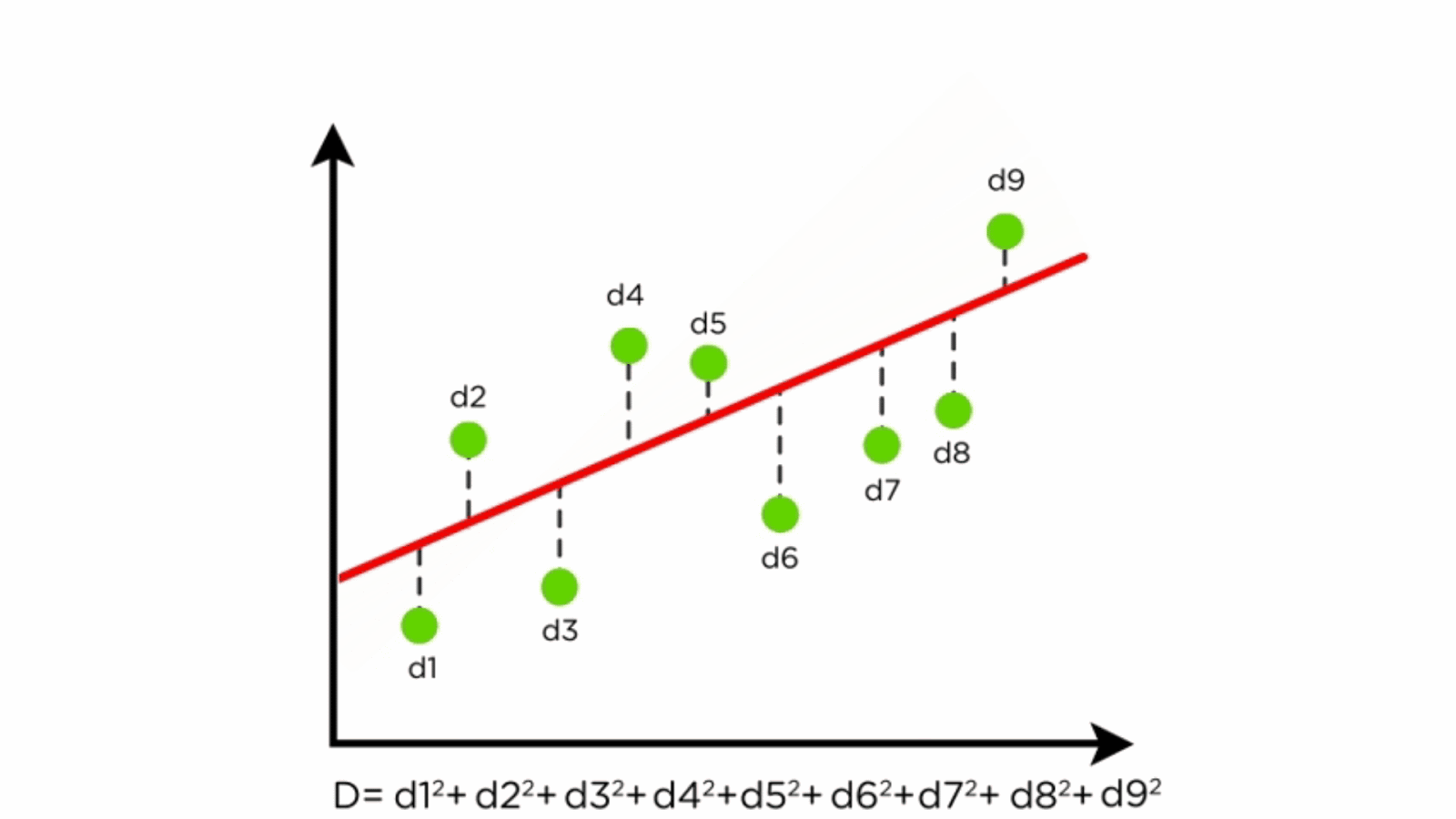
- Regression Line: Represents the relationship between X and Y.
- Residuals: Differences between predicted and actual values.
Linear Regression in tidymodels
Specification
linear_reg()
#> Linear Regression Model Specification (regression)
#>
#> Computational engine: lmengines & modes
show_engines("linear_reg") |>
mutate(specification = "linear_reg") |>
flextable()engine | mode | specification |
|---|---|---|
lm | regression | linear_reg |
glm | regression | linear_reg |
glmnet | regression | linear_reg |
stan | regression | linear_reg |
spark | regression | linear_reg |
keras | regression | linear_reg |
brulee | regression | linear_reg |
quantreg | quantile regression | linear_reg |
Example 

lm_mod <- linear_reg(mode = "regression", engine = "lm")
workflow() |>
add_formula(elevation ~ .) |>
add_model(lm_mod) |>
fit_resamples(resample = forested_folds) |>
collect_metrics()
#> # A tibble: 2 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 rmse standard 82.6 10 1.23 Preprocessor1_Model1
#> 2 rsq standard 0.971 10 0.000733 Preprocessor1_Model1Logistic Regression
Logistic Regression is used for binary classification tasks. It models the probability that an feature belongs to a category using the logistic (sigmoid) function. Unlike linear regression, which predicts continuous values, logistic regression predicts probabilities and applies a decision threshold to classify outcomes.
Why Use Logistic Regression?
Logistic Regression is widely used in machine learning due to its:
- Simplicity: Easy to implement and interpret.
- Efficiency: Computationally inexpensive, even on large datasets.
- Probabilistic Predictions: Outputs probabilities instead of hard classifications.
- Regularization Support: Extensions like L1 (Lasso) and L2 (Ridge) help prevent overfitting.
Components of Logistic Regression
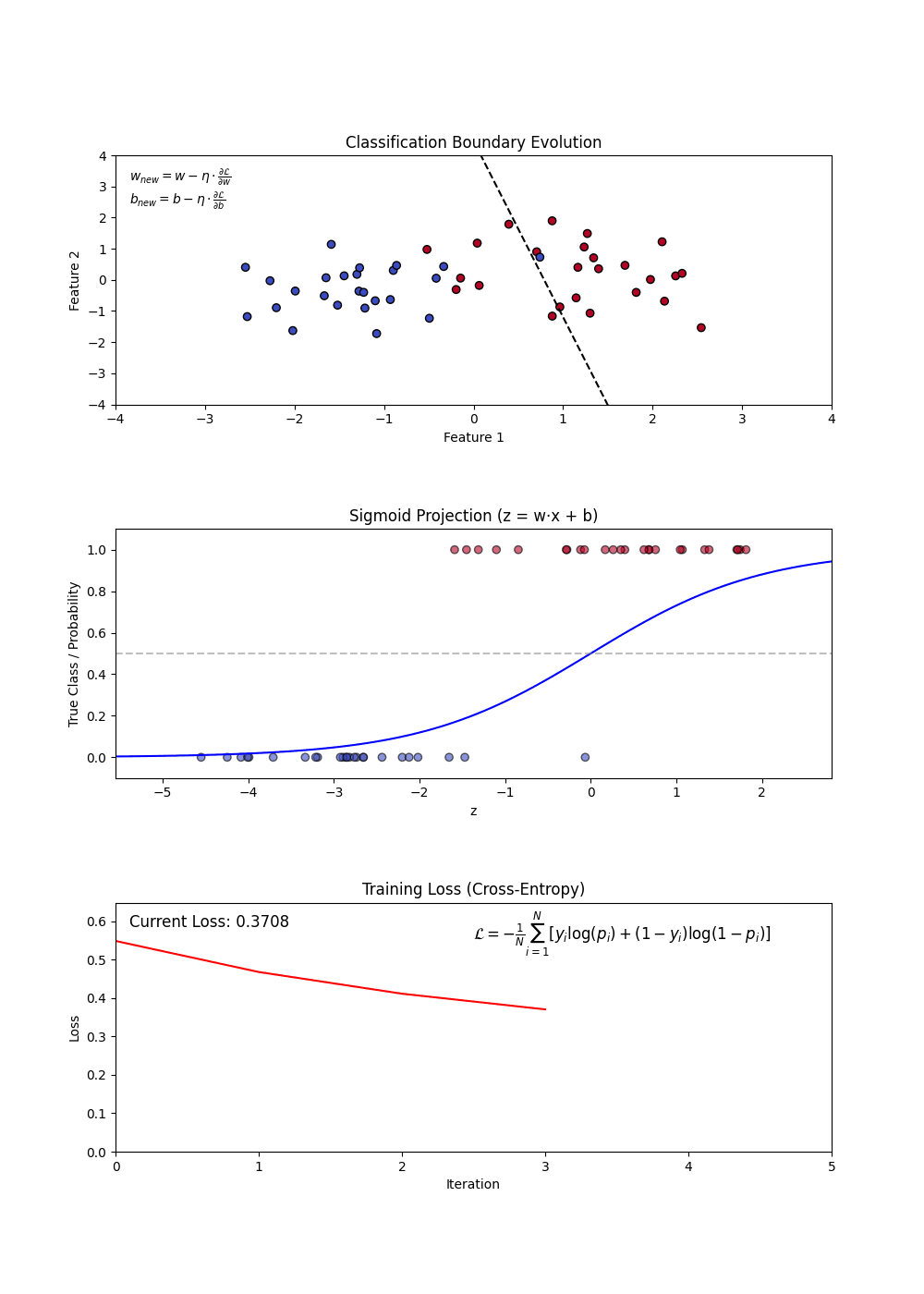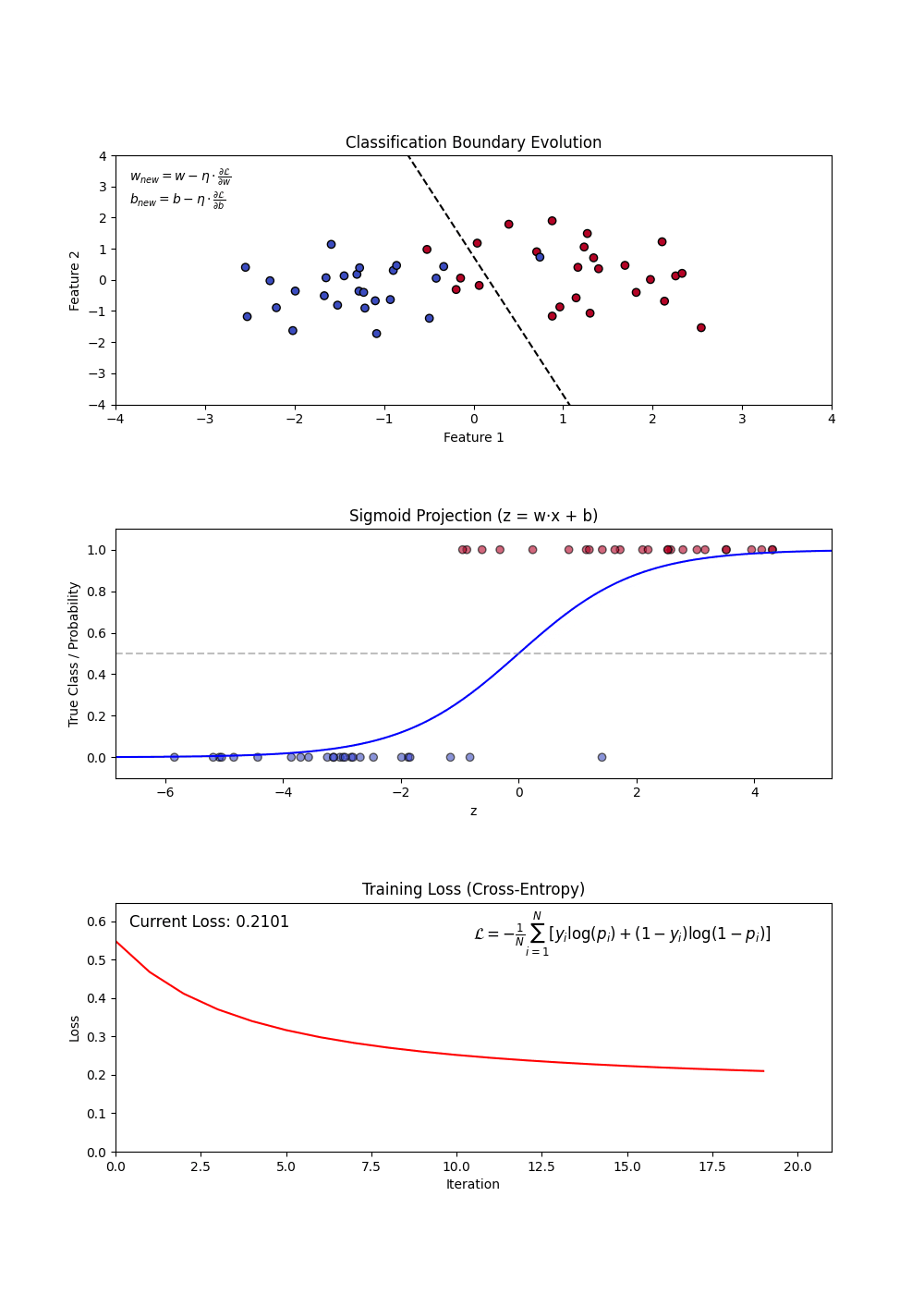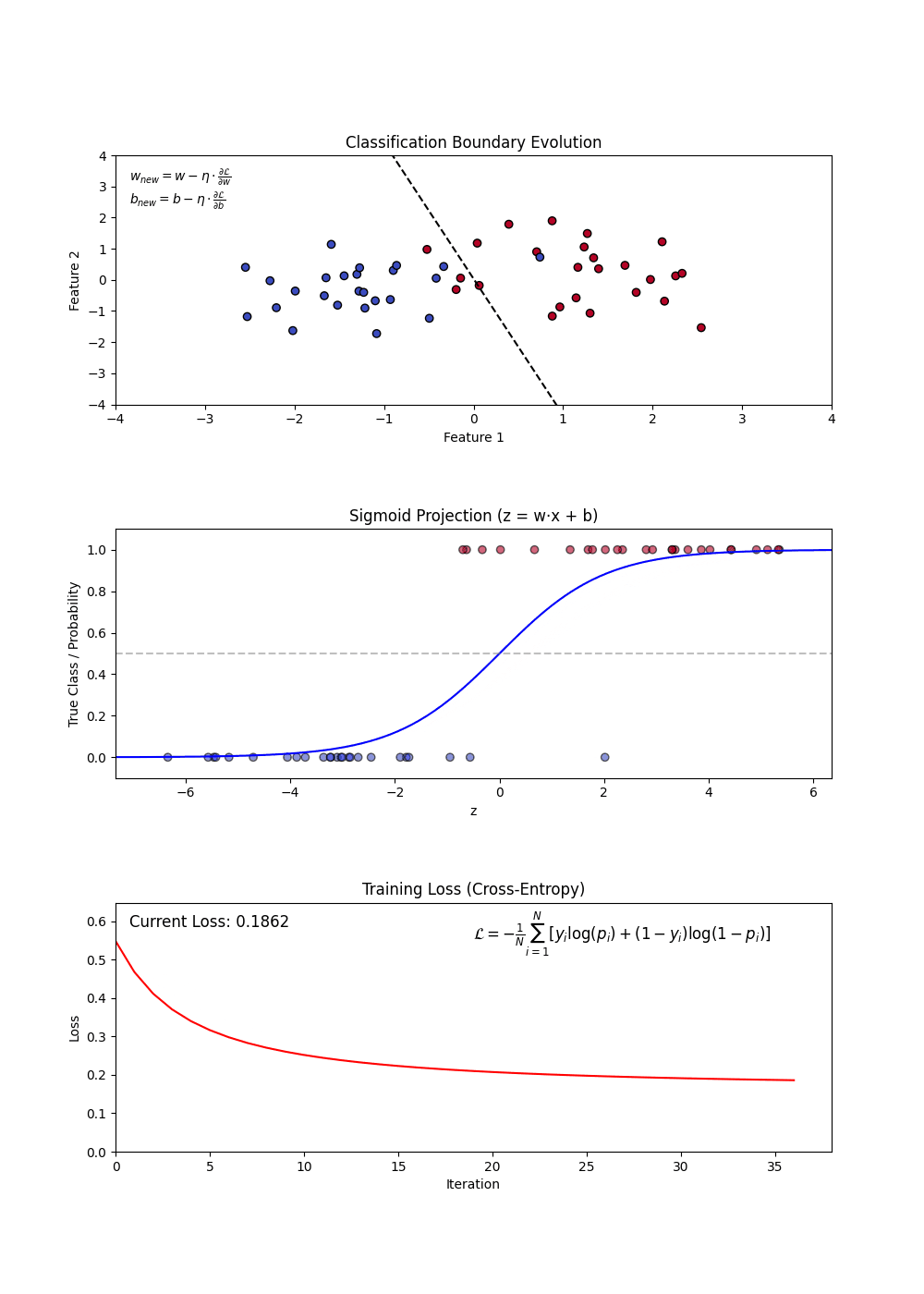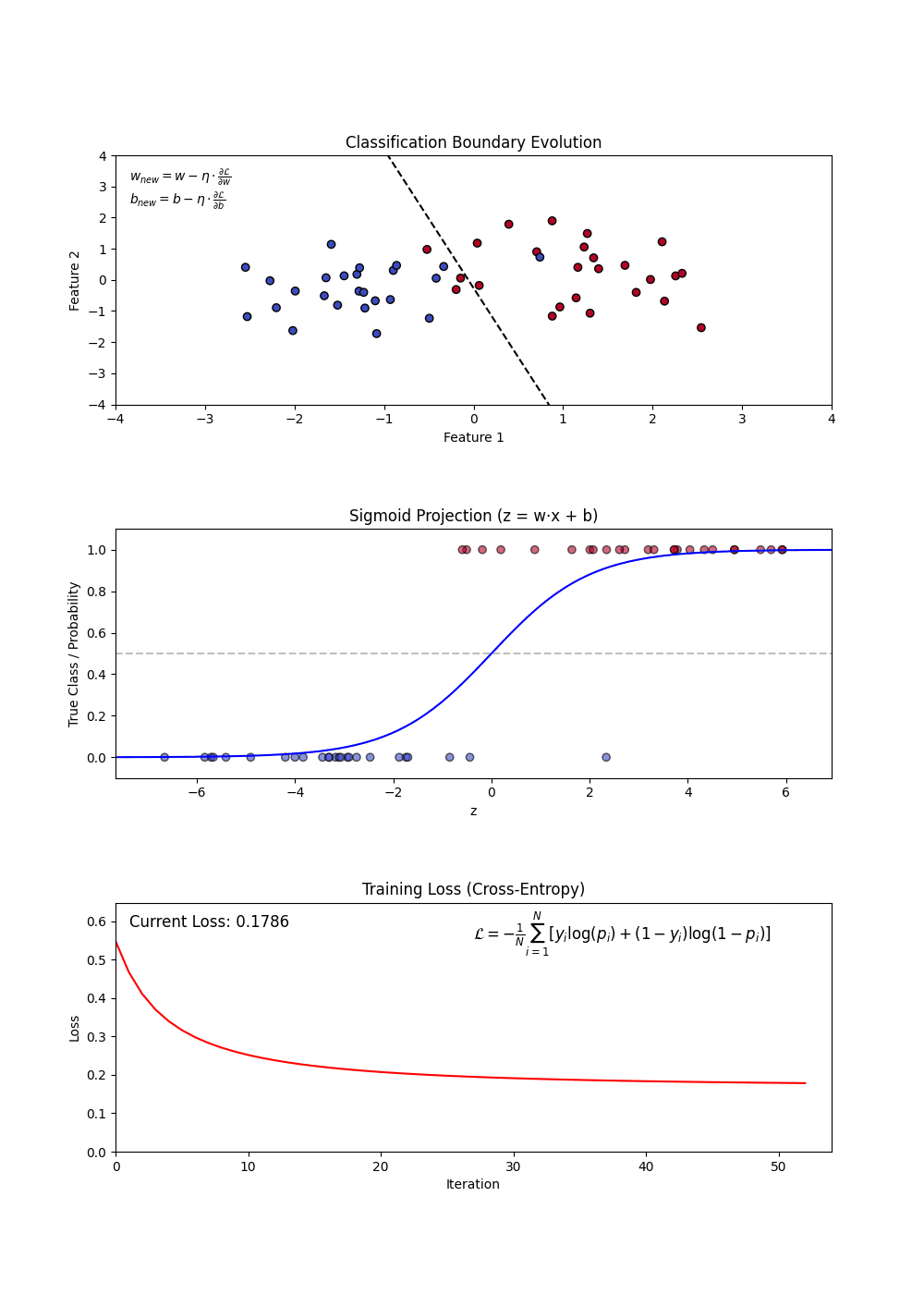
- Sigmoid Function: Converts linear outputs into probabilities between 0 and 1.
- Decision Boundary: A threshold (often 0.5) determines classification.
- Log-Loss (Binary Cross-Entropy): Measures the error between predicted probabilities and actual labels.
- Regularization (L1 and L2): Helps in feature selection and prevents overfitting.
Variants of Logistic Regression
Binary Logistic Regression: Used when the target variable has two classes (e.g., forested vs. not).
Multinomial Logistic Regression: Extends logistic regression to multiple classes without assuming ordering.
Ordinal Logistic Regression: Handles multi-class classification where order matters (e.g., rating scales).
Building a Logistic Regression Model
Constructing a Logistic Regression Model involves:
- Defining feature (X) and target variable (y).
- Applying the sigmoid function to map predictions to probabilities.
- Using a loss function (log-loss) to optimize model weights.
- Updating weights iteratively via gradient descent.
Hyperparameters in Logistic Regression
- penalty: Type of regularization (L1, L2, or none).
- mixture: A number between zero and one giving the proportion of L1 regularization (i.e. lasso) in the model
Advantages and Disadvantages
Advantages:
- Simple and interpretable.
- Efficient on large datasets.
- Outputs probabilities for uncertainty estimation.
- Works well when data is linearly separable.
Disadvantages:
- Assumes a linear decision boundary.
- Sensitive to outliers.
- Can underperform on complex, non-linear data.
Logistic Regression in tidymodels
Specification
logistic_reg()
#> Logistic Regression Model Specification (classification)
#>
#> Computational engine: glmengines & modes
show_engines('logistic_reg') |>
mutate(specification = "logistic_reg") |>
flextable()engine | mode | specification |
|---|---|---|
glm | classification | logistic_reg |
glmnet | classification | logistic_reg |
LiblineaR | classification | logistic_reg |
spark | classification | logistic_reg |
keras | classification | logistic_reg |
stan | classification | logistic_reg |
brulee | classification | logistic_reg |
Example
log_model <- logistic_reg(penalty = .01) |>
set_engine("glmnet") |>
set_mode('classification')
workflow() |>
add_recipe(forested_recipe) |>
add_model(log_model) |>
fit_resamples(resample = forested_folds) |>
collect_metrics()
#> # A tibble: 3 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 accuracy binary 0.893 10 0.00429 Preprocessor1_Model1
#> 2 brier_class binary 0.0786 10 0.00330 Preprocessor1_Model1
#> 3 roc_auc binary 0.958 10 0.00304 Preprocessor1_Model1Conclusion
Logistic Regression is a fundamental classification algorithm known for its simplicity and efficiency. It serves as a strong baseline model and is widely applied in domains like medical diagnosis, credit scoring, and fraud detection. With proper tuning and regularization, it remains a powerful tool in predictive modeling.
3. Decision Tree
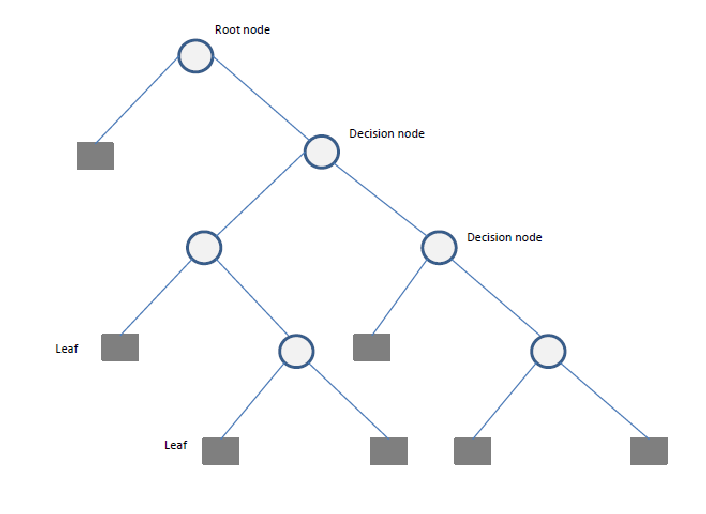
A Decision Tree is a flowchart-like structure used for decision-making and predictive modeling. It consists of nodes representing decisions, branches indicating possible outcomes, and leaf nodes that represent final classifications or numerical outputs. Decision Trees are widely used in both classification and regression tasks.
Why Use Decision Trees?
Decision Trees are popular due to their: - Simplicity and Interpretability: Easy to understand and visualize. - Non-Linearity Handling: Can capture complex relationships in data. - Feature Importance: Helps in identifying the most influential features. - Minimal Data Preprocessing: Requires little to no feature scaling.
Components of a Decision Tree
- Root Node: The starting point representing the entire dataset.
- Decision Nodes: Intermediate nodes where a dataset is split based on a feature.
- Splitting: The process of dividing a node into sub-nodes based on a feature value.
- Pruning: The process of removing unnecessary branches to avoid overfitting.
- Leaf Nodes: The terminal nodes that provide the final output (class label or numerical prediction).
Building a Decision Tree
Constructing a Decision Tree involves:
- Selecting the best feature(s) to split the data.
- Splitting the data into subsets.
- Repeating this process recursively until stopping criteria (e.g., depth, minimum samples per leaf) are met.
- Pruning the tree if necessary to reduce overfitting.
Splitting Criteria
Several criteria can be used to determine the best split:
- Gini Impurity: Measures the impurity of a node, used in Classification and Regression Trees (CART).
- Entropy (Information Gain): Measures the randomness in a dataset.
- Mean Squared Error (MSE): Used for regression trees to minimize variance within nodes.
Hyperparameters in Decision Trees
Key hyperparameters include:
- cost_complexity: complexity parameter for pruning
- tree_depth: maximum depth of the tree
- min_n: minimum number of observations in a node
Advantages and Disadvantages
Advantages:
- Easy to interpret and explain.
- Can handle both numerical and categorical data.
- Requires minimal data preparation.
- Works well with missing values.
Disadvantages:
- Prone to overfitting, especially on small datasets.
- Can be unstable; small changes in data can lead to drastically different splits.
- Biased towards features with more levels.
Decision Tree using tidymodels
Specification
decision_tree()
#> Decision Tree Model Specification (unknown mode)
#>
#> Computational engine: rpartengines & modes
show_engines('decision_tree') |>
mutate(specification = "decision_tree") |>
flextable()engine | mode | specification |
|---|---|---|
rpart | classification | decision_tree |
rpart | regression | decision_tree |
C5.0 | classification | decision_tree |
spark | classification | decision_tree |
spark | regression | decision_tree |
Example
dt_model <- decision_tree(tree_depth = 10, min_n = 3) |>
set_engine("rpart") |>
set_mode('classification')
workflow() |>
add_recipe(forested_recipe) |>
add_model(dt_model) |>
fit_resamples(resample = forested_folds) |>
collect_metrics()
#> # A tibble: 3 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 accuracy binary 0.891 10 0.00361 Preprocessor1_Model1
#> 2 brier_class binary 0.0911 10 0.00329 Preprocessor1_Model1
#> 3 roc_auc binary 0.911 10 0.00526 Preprocessor1_Model1Conclusion
Decision Trees are a powerful and interpretable tool for both classification and regression problems. While they have limitations, techniques like pruning and ensemble methods (e.g., Random Forests) can help mitigate their weaknesses. Understanding Decision Trees within the tidymodels framework makes them accessible for practical applications in environmental science.
4. Random Forest
Random Forests provide an ensemble learning method that constructs multiple decision trees and aggregates their predictions to improve accuracy and reduce overfitting. It is used for both classification and regression tasks.
Why Use Random Forest?
Random Forest offers several advantages: - Higher Accuracy: By combining multiple decision trees, it reduces variance and improves predictive performance. - Robustness to Overfitting: By averaging multiple trees, it mitigates the risk of overfitting. - Feature Importance Analysis: Helps identify the most influential features. - Handles Missing Data: Can work well with incomplete datasets.
Components of a Random Forest
- Multiple Decision Trees: The fundamental building blocks.
- Bootstrap Sampling: Randomly selects subsets of data to train each tree.
- Feature Subsetting: Uses a random subset of features at each split to improve diversity among trees.
- Aggregation (Bagging): Combines the outputs of individual trees through voting (classification) or averaging (regression).
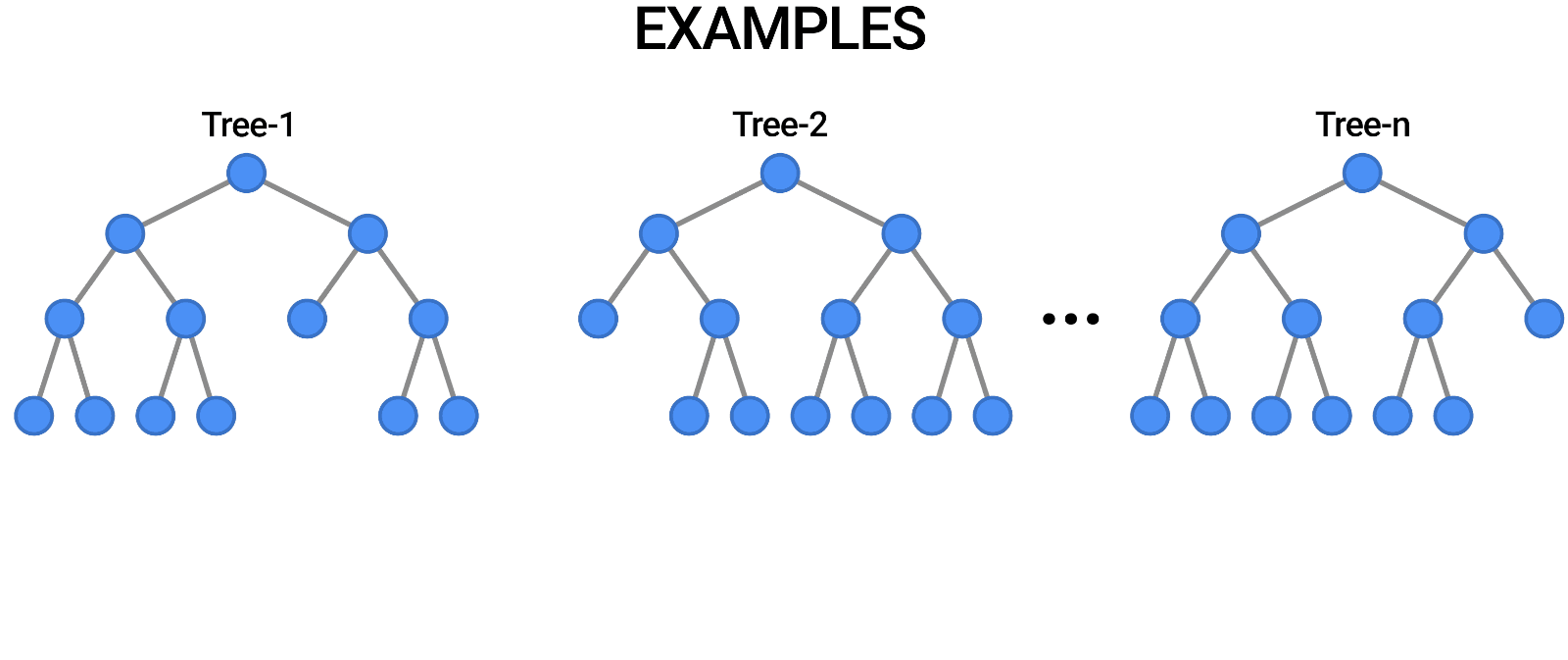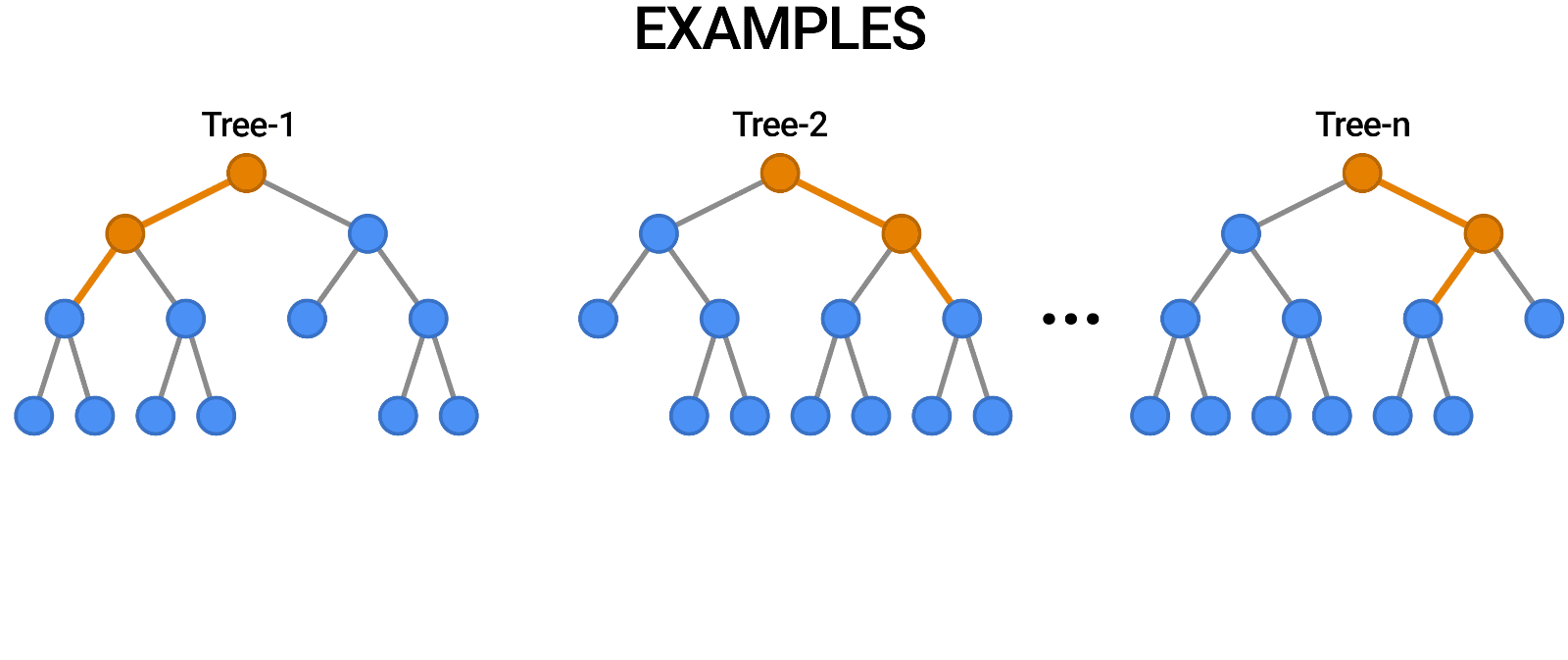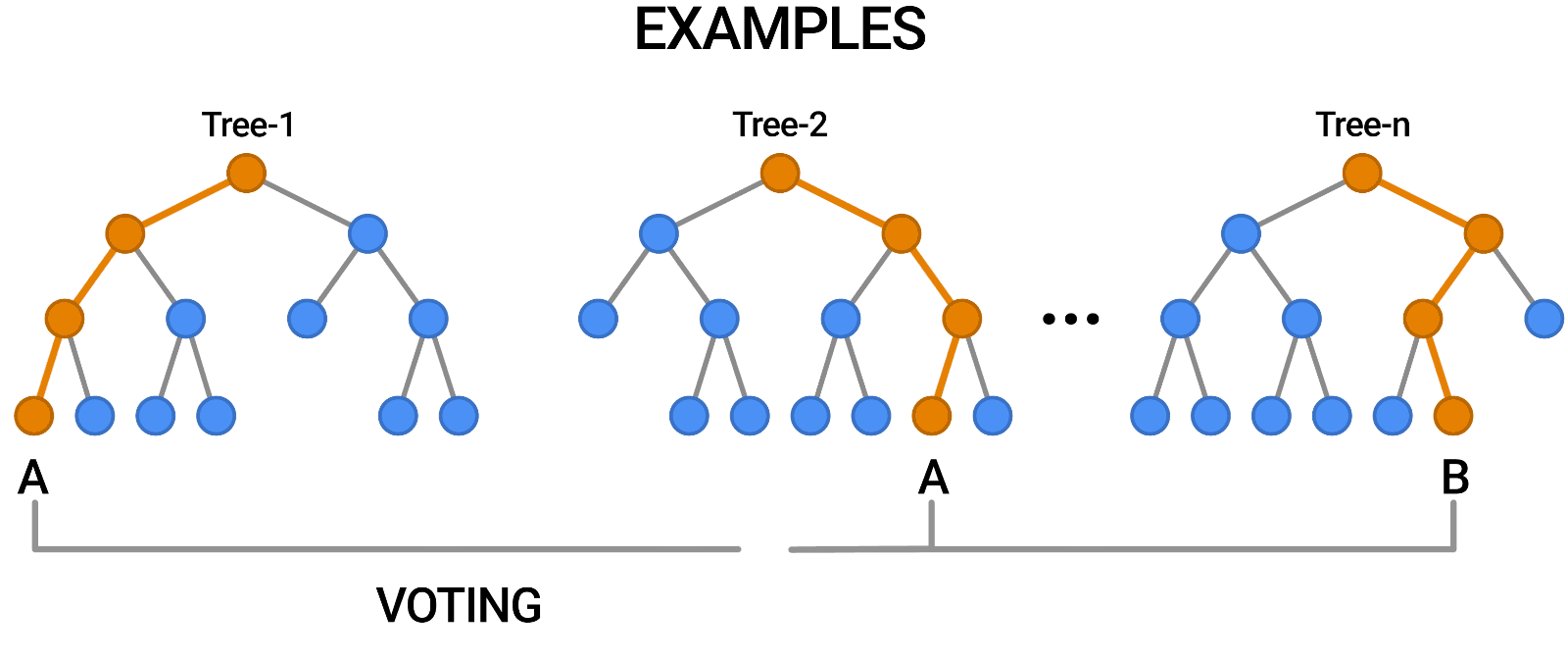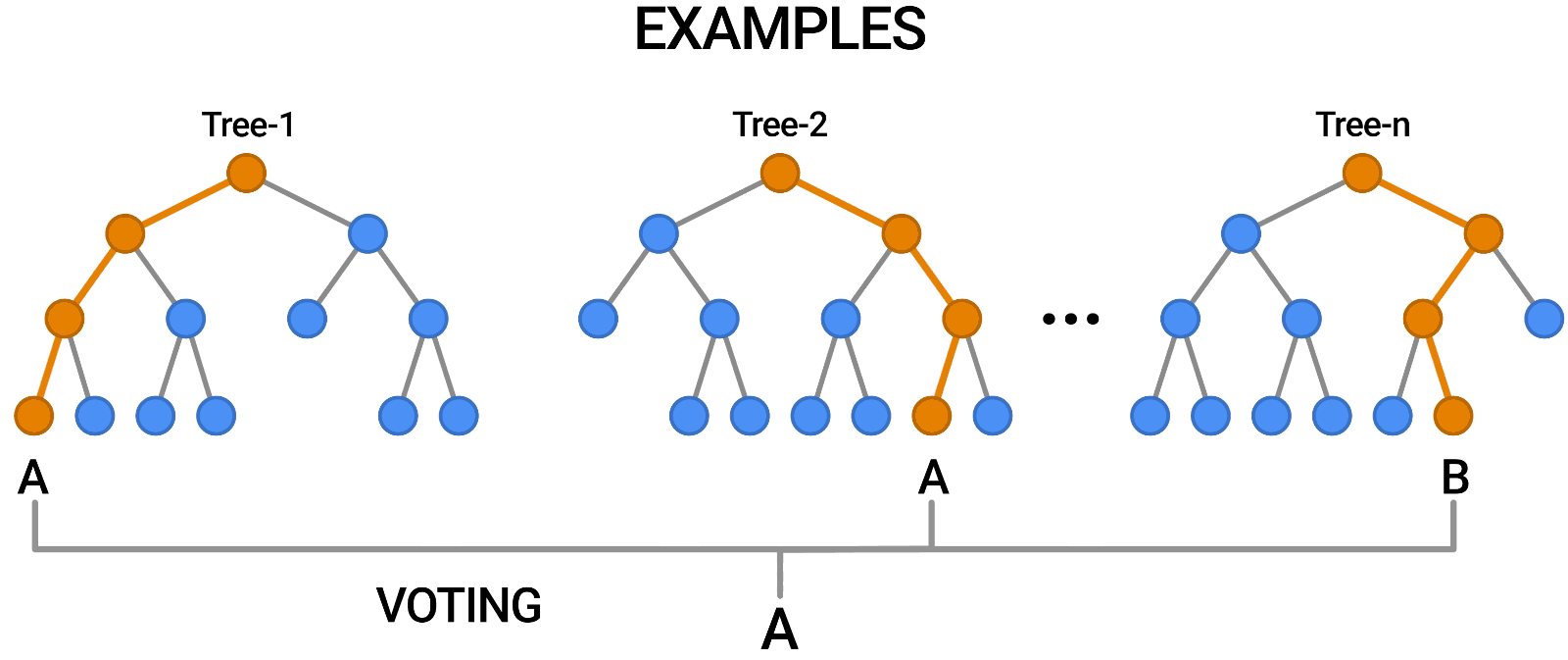
Building a Random Forest
Constructing a Random Forest involves:
- Creating multiple bootstrap samples from the dataset.
- Training a decision tree on each bootstrap sample using a random subset of features.
- Aggregating predictions from all trees to produce the final output.
Hyperparameters in Random Forest
- Number of Trees (
ntree): Determines how many trees are included in the forest. - Maximum Depth (
max_depth): Limits the depth of individual trees to prevent overfitting. - Minimum Samples per Leaf (
min_n): Specifies the minimum number of observations required in a leaf node. - Number of Features (
mtry): Controls how many features are randomly selected at each split.
Advantages and Disadvantages
Advantages:
- Handles large datasets with high-dimensional feature spaces.
- Reduces overfitting by averaging multiple decision trees.
- Works well with both categorical and numerical data.
- Provides built-in feature selection.
Disadvantages:
- Requires more computational resources than a single decision tree.
- Less interpretable than a single decision tree.
- Can be slower to make predictions due to ensemble averaging.
Random Forest Implementation using Tidymodels
Specification
rand_forest()
#> Random Forest Model Specification (unknown mode)
#>
#> Computational engine: rangerengines & modes
show_engines('rand_forest') |>
mutate(specification = "rand_forest") |>
flextable()engine | mode | specification |
|---|---|---|
ranger | classification | rand_forest |
ranger | regression | rand_forest |
randomForest | classification | rand_forest |
randomForest | regression | rand_forest |
spark | classification | rand_forest |
spark | regression | rand_forest |
Example
# Define a Random Forest model
rf_model <- rand_forest(trees = 10) |>
set_engine("ranger", importance = "impurity") |>
set_mode("classification")
workflow() |>
add_recipe(forested_recipe) |>
add_model(rf_model) |>
fit_resamples(resample = forested_folds) |>
collect_metrics()
#> # A tibble: 3 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 accuracy binary 0.909 10 0.00386 Preprocessor1_Model1
#> 2 brier_class binary 0.0677 10 0.00232 Preprocessor1_Model1
#> 3 roc_auc binary 0.964 10 0.00213 Preprocessor1_Model1Conclusion
Random Forest is a powerful ensemble learning method that improves upon decision trees by reducing overfitting and increasing accuracy. By leveraging the tidymodels framework in R, it can be effectively applied to various environmental science problems.
Boosting Machines
Boosting is an ensemble learning technique that builds multiple weak models (often decision trees) sequentially, with each model correcting the errors of its predecessor. This iterative process improves predictive accuracy and reduces bias, making boosting one of the most powerful machine learning methods. Popular implementations include Gradient Boosting Machines (GBM), XGBoost (Extreme Gradient Boosting), LightGBM, and CatBoost.
Why Use Boosting Machines?
XGBoost is widely used in machine learning due to its: - High Accuracy: Often outperforms other algorithms in predictive tasks. - Efficiency: Optimized for speed and parallel processing. - Feature Importance: Provides insights into which features influence predictions. - Robustness to Overfitting: Uses regularization techniques to enhance generalization.
Components of Gradient Boosting
- Weak Learners: Typically small decision trees (stumps).
- Gradient Descent Optimization: Each tree corrects the residual errors of the previous trees.
- Learning Rate (
eta): Controls the contribution of each tree to the final prediction. - Regularization (
lambdaandalpha): Penalizes complex trees to prevent overfitting.
Popular Boosting Algorithms
Gradient Boosting Machines (GBM): A general boosting method that minimizes loss using gradient descent.
XGBoost (Extreme Gradient Boosting): An optimized version of GBM that is computationally efficient and includes regularization.
LightGBM: Designed for efficiency on large datasets by using histogram-based learning and reducing memory usage.
CatBoost: Specialized for categorical data, using ordered boosting and permutation techniques to reduce bias.
Building an XGBoost Model
The process involves:
- Initializing predictions with a simple model (e.g., the mean for regression).
- Computing the residual errors.
- Training a new tree to predict these residuals.
- Updating the predictions by adding a fraction of the new tree’s output.
- Repeating until a stopping criterion is met (e.g., a maximum number of trees or performance threshold).
Hyperparameters in XGBoost
nrounds(Number of Trees): The number of boosting iterations.max_depth: The maximum depth of trees.eta(Learning Rate): Controls how much each tree contributes to the model.gamma: Minimum loss reduction required to split a node.colsample_bytree: Fraction of features to consider for each tree.
Advantages and Disadvantages
Advantages:
- Handles large datasets efficiently.
- Reduces bias and variance compared to single decision trees.
- Provides feature importance analysis.
- Can be used for both classification and regression.
Disadvantages:
- More complex and harder to interpret than a single decision tree.
- Requires tuning of hyperparameters for optimal performance.
- Can overfit if not properly regularized.
Boost Implementation using Tidymodels
# Define an XGBoost model
b_model <- boost_tree() |>
set_engine("xgboost") |>
set_mode("classification")
workflow() |>
add_recipe(forested_recipe) |>
add_model(b_model) |>
fit_resamples(resample = forested_folds) |>
collect_metrics()
#> # A tibble: 3 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 accuracy binary 0.909 10 0.00461 Preprocessor1_Model1
#> 2 brier_class binary 0.0657 10 0.00259 Preprocessor1_Model1
#> 3 roc_auc binary 0.969 10 0.00197 Preprocessor1_Model1Conclusion
XGBoost is a powerful ensemble learning method that significantly improves predictive accuracy while mitigating overfitting. By leveraging tidymodels in R, environmental scientists can apply XGBoost to various challenges such as climate modeling, pollution forecasting, and disaster risk assessment.
Support Vector Machine (SVM)
Support Vector Machines (SVM) is a supervised learning algorithm used for classification and regression tasks. It works by finding the optimal hyperplane that best separates data points into different classes.
2. Why Use SVM?
SVM is widely used in machine learning due to its:
- Effective for High-Dimensional Data: Works well with datasets with many features.
- Robustness to Overfitting: Uses regularization techniques to prevent overfitting.
- Versatility: Can be applied to linear and non-linear classification tasks using different kernel functions.
- Support for Small Datasets: Works well when the number of samples is limited.
3. Components of SVM
- Support Vectors: Data points that define the hyperplane.
- Margin: The distance between the hyperplane and the nearest support vectors.
- Kernel Functions: Transform data to a higher dimension to make it separable.
Building an SVM Model
The process involves:
- Selecting an appropriate kernel function (linear, polynomial, radial basis function, etc.).
- Finding the hyperplane that best separates the data.
- Maximizing the margin between the hyperplane and the closest points.
- Using a regularization parameter (
C) to control trade-offs between a wider margin and misclassifications.
Hyperparameters in SVM
Key hyperparameters include:
- C (Regularization Parameter): Controls the trade-off between maximizing margin and minimizing classification error.
- kernel: Determines the transformation of input space (e.g., linear, radial basis function (RBF), polynomial).
- gamma: Controls the influence of individual training
Advantages and Disadvantages
Advantages:
- Works well with small to medium-sized datasets.
- Effective for both linear and non-linear classification.
- Handles high-dimensional spaces well.
Disadvantages:
- Computationally expensive for large datasets.
- Requires careful tuning of hyperparameters.
- Not as interpretable as decision trees.
SVM Implementation using Tidymodels
# Define an SVM model
svm_model <- svm_poly() |>
set_engine("kernlab") |>
set_mode("classification")
workflow() |>
add_recipe(forested_recipe) |>
add_model(svm_model) |>
fit_resamples(resample = forested_folds) |>
collect_metrics()
#> # A tibble: 3 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 accuracy binary 0.905 10 0.00421 Preprocessor1_Model1
#> 2 brier_class binary 0.0744 10 0.00320 Preprocessor1_Model1
#> 3 roc_auc binary 0.956 10 0.00293 Preprocessor1_Model1Conclusion
Support Vector Machines (SVM) is a powerful algorithm for classification and regression tasks, especially when working with high-dimensional datasets. By leveraging tidymodels in R, environmental scientists can apply SVM to various challenges such as land cover classification, pollution prediction, and climate modeling.
Neural Networks
A Neural Network is a computational model inspired by the structure of the human brain. It consists of layers of interconnected neurons that transform input data to learn patterns and make predictions. Neural Networks are widely used for tasks such as image recognition, natural language processing, and time series forecasting.
Why Use Neural Networks?
Neural Networks are popular due to their:
- Ability to Model Complex Patterns: Can capture intricate relationships in data.
- Scalability: Performs well with large datasets.
- Feature Learning: Automatically extracts relevant features from raw data.
- Generalization: Can adapt to different types of data with proper training.
Components of a Neural Network
Neurons: The fundamental units that receive, process, and transmit information.
Input Layer: The initial layer that receives raw data.
Hidden Layers: Intermediate layers where computations occur to learn features.
Output Layer: Produces the final prediction or classification.
Weights & Biases: Parameters that are optimized during training.
Activation Functions: Functions like ReLU, Sigmoid, and Softmax that introduce non-linearity.
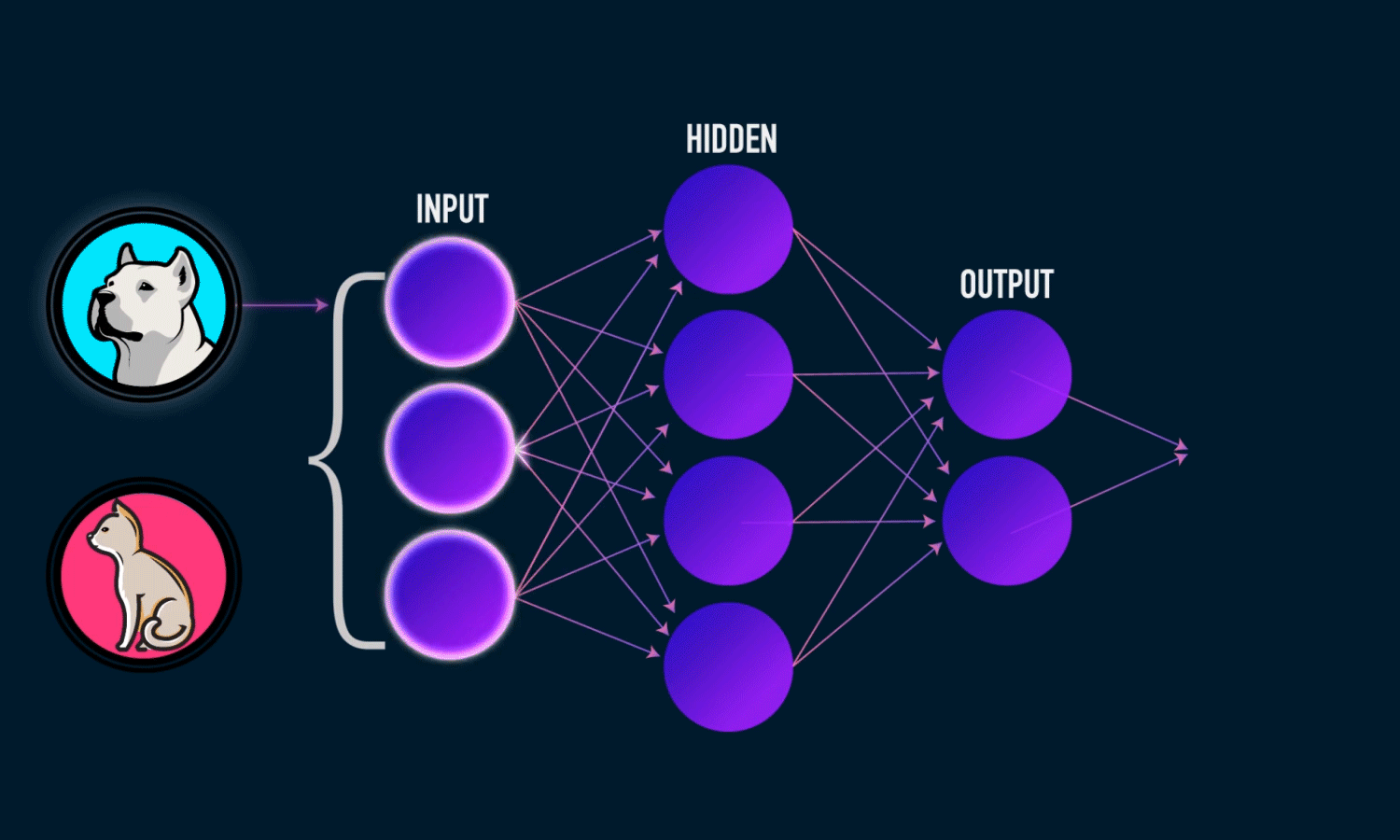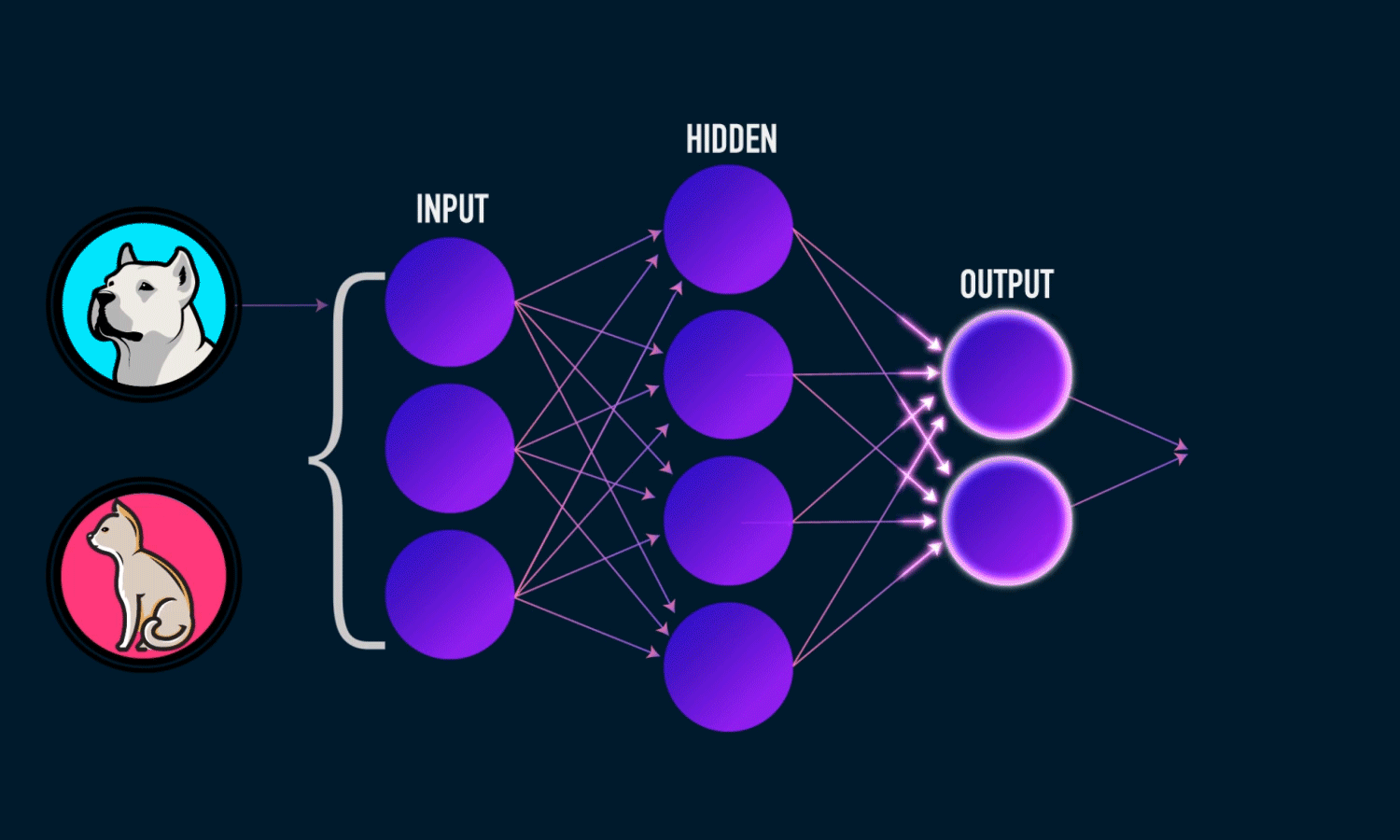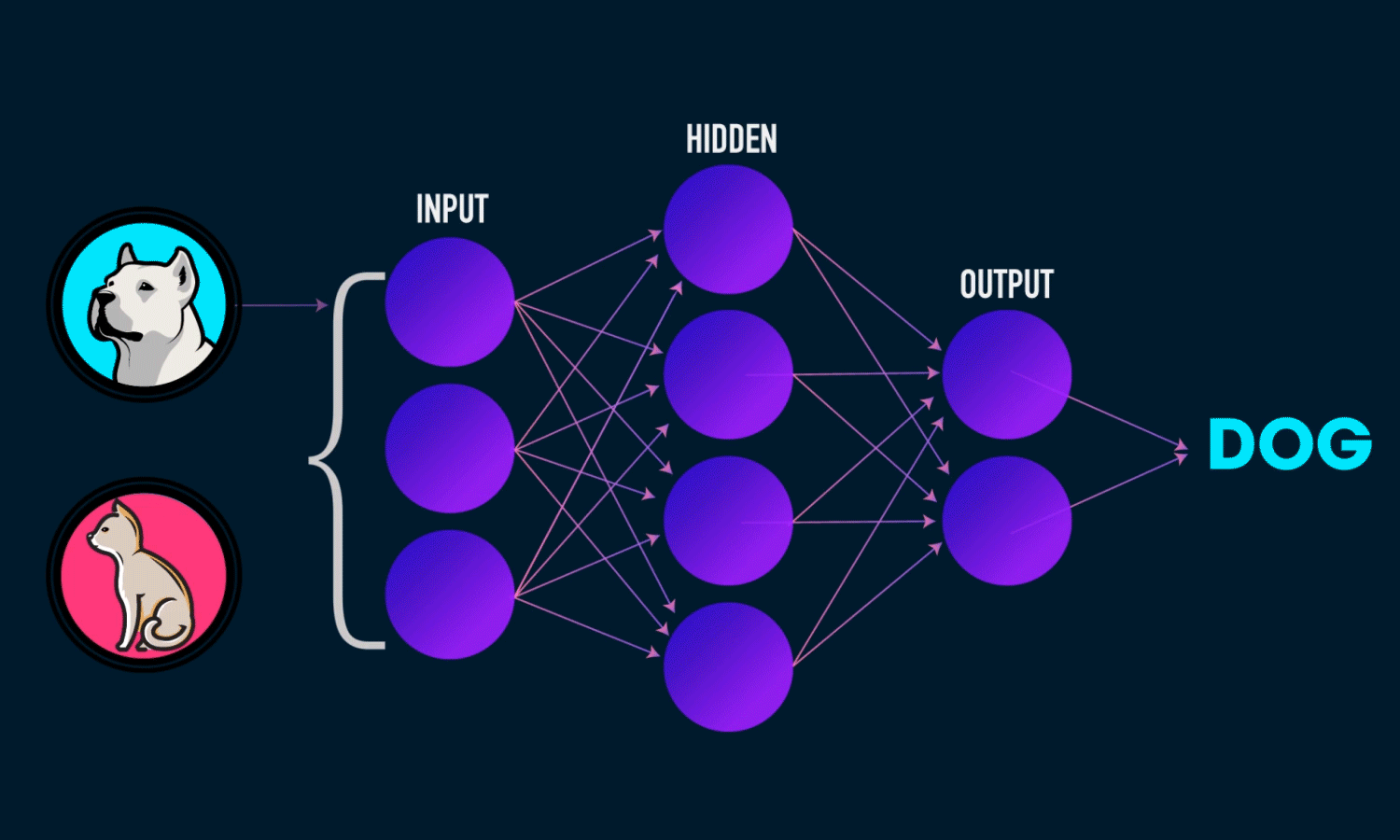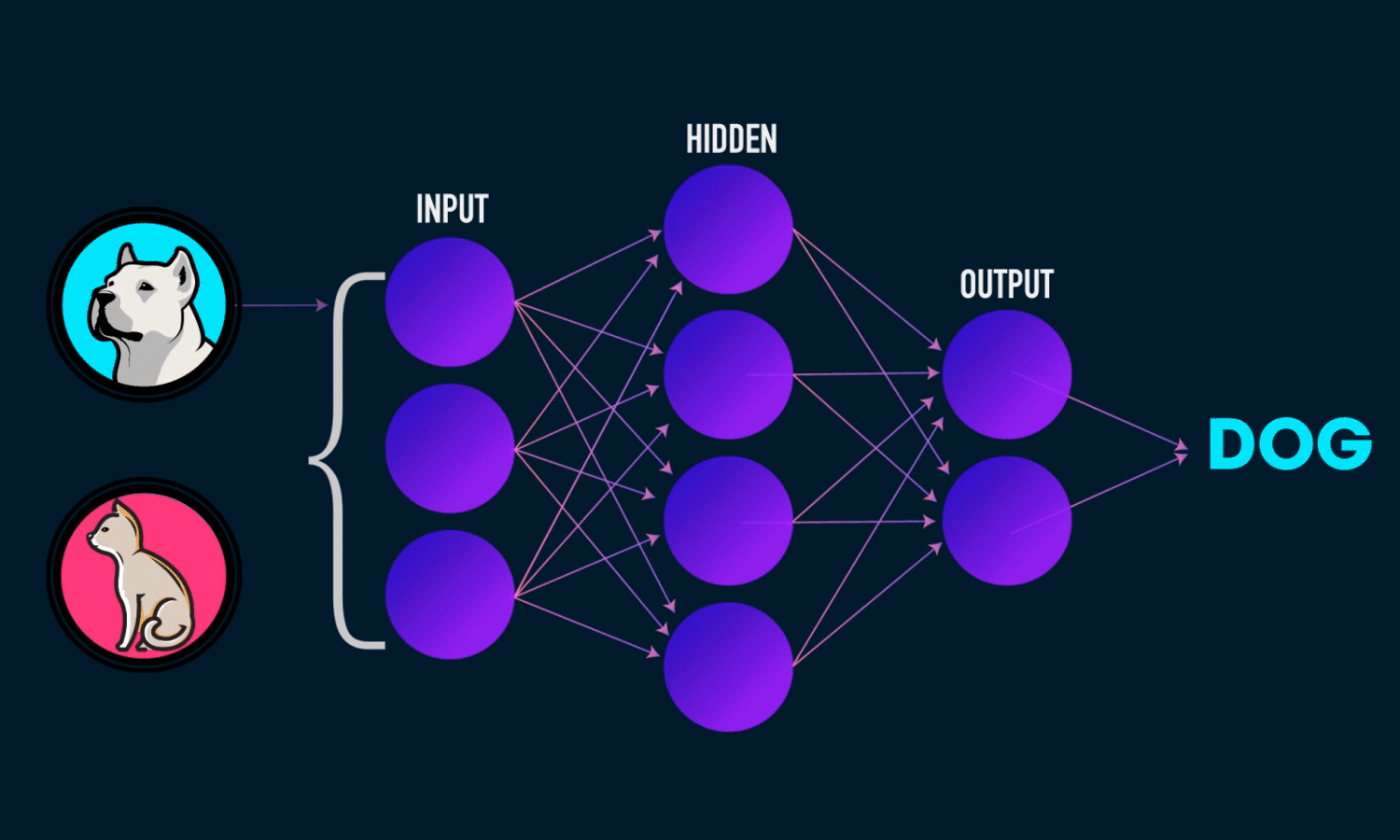
Training a Neural Network
The training process involves:
- Forward Propagation: Inputs pass through the network, producing an output.
- Loss Calculation: The difference between predicted and actual values is measured.
- Backpropagation: Errors are propagated backward to update weights.
- Optimization: Gradient descent (or its variants) adjusts weights to minimize loss.
- Iteration: The process repeats over multiple epochs until convergence.
Hyperparameters in Neural Networks
- hidden_units: Number of neurons in hidden layers.
- penalty: Regularization term to prevent overfitting.
- dropout: Fraction of neurons randomly dropped during training.
- epochs: Number of training iterations.
- activation: Activation function for neurons (e.g., ReLU, Sigmoid).
- learn_rate: Step size for weight updates.
Advantages and Disadvantages
Advantages:
- Can model complex, non-linear relationships.
- Works well with high-dimensional data.
- Automatically extracts features from data.
Disadvantages:
- Requires large datasets for effective training.
- Computationally expensive.
- Difficult to interpret compared to simpler models like Decision Trees.
Varients of Neural Networks
mlp() → Generic MLP model (uses “nnet”, “keras”, or “brulee” as an engine).
bag_mlp() → Bagged MLP model using “nnet” (reduces variance).
brulee::mlp() → MLP model using torch via brulee (more scalable and flexible).
Which one you choose depends on your dataset size, computational resources, and need for ensembling. If you need better scalability, brulee::mlp() is likely a better choice. If you want a quick MLP with some regularization, mlp() with “nnet” or “keras” works. If variance reduction is a concern, bag_mlp() is a solid option.
Neural Network Implementation
mlp() defines a multilayer perceptron model (a.k.a. a single layer, feed-forward neural network). This function can fit classification and regression models.
Specification
mlp()
#> Single Layer Neural Network Model Specification (unknown mode)
#>
#> Computational engine: nnetengines & modes
show_engines("mlp") |>
mutate(specification = "mlp") |>
flextable()engine | mode | specification |
|---|---|---|
keras | classification | mlp |
keras | regression | mlp |
nnet | classification | mlp |
nnet | regression | mlp |
brulee | classification | mlp |
brulee | regression | mlp |
brulee_two_layer | classification | mlp |
brulee_two_layer | regression | mlp |
Example
nn_model <- mlp(hidden_units = 5, penalty = 0.01) |>
set_engine("nnet") |>
set_mode("classification")
workflow() |>
add_recipe(forested_recipe) |>
add_model(nn_model) |>
fit_resamples(resample = forested_folds) |>
collect_metrics()
#> # A tibble: 3 × 6
#> .metric .estimator mean n std_err .config
#> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 accuracy binary 0.908 10 0.00462 Preprocessor1_Model1
#> 2 brier_class binary 0.118 10 0.00139 Preprocessor1_Model1
#> 3 roc_auc binary 0.965 10 0.00211 Preprocessor1_Model1Conclusion
Neural Networks are a powerful tool for solving complex problems in various domains. While they require significant computational resources, proper training and regularization techniques can make them highly effective for predictive modeling. Understanding Neural Networks within the torch framework allows for practical applications in data science and environmental modeling.
Wrap up
Lets combine all the models and evaluate their performance using cross-validation.
We learned about cross-validation last Monday and its importance in evaluating model performance.
We will use a workflow set (seen last Wednesday) to fit multiple models at once and compare their performance.
Remember, we have not implmented any hyperparameter tuning yet, so these are just base models.
forested_folds <- vfold_cv(forested_train, v = 10)
wf <- workflow_set(list(forested_recipe),
list(log_model,
dt_model,
rf_model,
b_model,
svm_model,
nn_model)) |>
workflow_map('fit_resamples', resamples = forested_folds)Model Performance Comparision
autoplot(wf) +
theme_linedraw(18) +
theme(legend.position = 'bottom')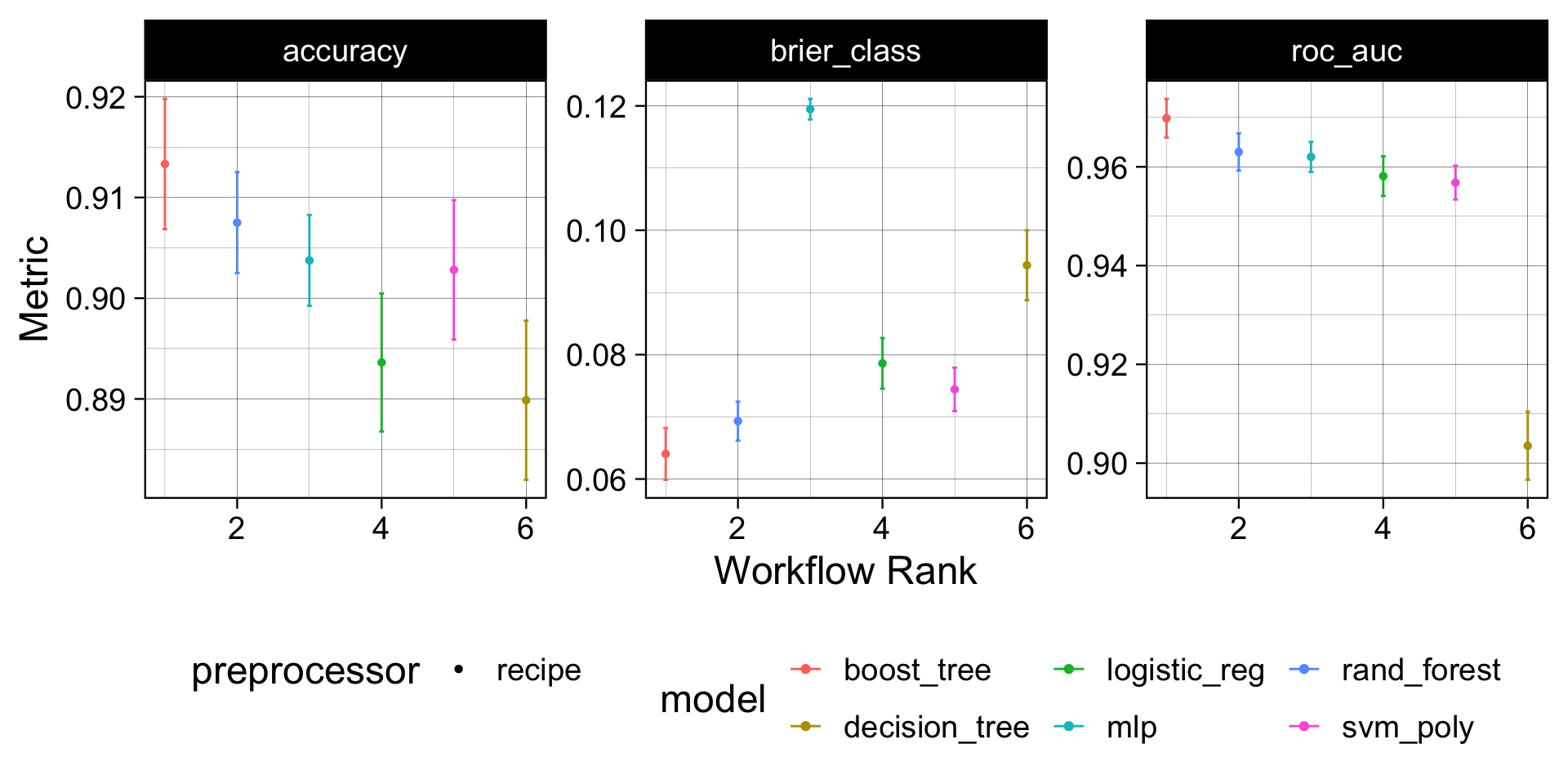
Model Evaluation
Understanding the boost model provided the best performance out of the box we can (1) select that model (2)
final_fit <- workflow() |>
add_recipe(forested_recipe) |>
# Selected Model
add_model(b_model) |>
# Trained with full training dataset
fit(data = forested_train) |>
# Validated against hold out data
augment(new_data = forested_test)
# Final Results!
metrics(final_fit, truth = forested, estimate = .pred_class)
#> # A tibble: 2 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy binary 0.917
#> 2 kap binary 0.833
conf_mat(final_fit, truth = forested, estimate = .pred_class)
#> Truth
#> Prediction Yes No
#> Yes 910 86
#> No 61 720The whole game - status update
Recaping
library(tidymodels)
library(forested)
# Set a seed
set.seed(123)
# IntitalizeInitialize Split
forested_split <- initial_split(forested, prop = 0.8)
forested_train <- training(forested_split)
forested_test <- testing(forested_split)
# Build Resamples
forested_folds <- vfold_cv(forested_train, v = 10)
# Set a model specification with mode (default engine)
dt_mod <- decision_tree(cost_complexity = 0.0001, mode = "classification")
# Bare bones workflow & fit
forested_wflow <- workflow(forested ~ ., dt_mod)
forested_fit <- fit(forested_wflow, forested_train)
# Extracting Predictions:
augment(forested_fit, new_data = forested_train)
#> # A tibble: 5,685 × 22
#> .pred_class .pred_Yes .pred_No forested year elevation eastness northness
#> <fct> <dbl> <dbl> <fct> <dbl> <dbl> <dbl> <dbl>
#> 1 No 0.0114 0.989 No 2016 464 -5 -99
#> 2 Yes 0.636 0.364 Yes 2016 166 92 37
#> 3 No 0.0114 0.989 No 2016 644 -85 -52
#> 4 Yes 0.977 0.0226 Yes 2014 1285 4 99
#> 5 Yes 0.977 0.0226 Yes 2013 822 87 48
#> 6 Yes 0.808 0.192 Yes 2017 3 6 -99
#> 7 Yes 0.977 0.0226 Yes 2014 2041 -95 28
#> 8 Yes 0.977 0.0226 Yes 2015 1009 -8 99
#> 9 No 0.0114 0.989 No 2017 436 -98 19
#> 10 No 0.0114 0.989 No 2018 775 63 76
#> # ℹ 5,675 more rows
#> # ℹ 14 more variables: roughness <dbl>, tree_no_tree <fct>, dew_temp <dbl>,
#> # precip_annual <dbl>, temp_annual_mean <dbl>, temp_annual_min <dbl>,
#> # temp_annual_max <dbl>, temp_january_min <dbl>, vapor_min <dbl>,
#> # vapor_max <dbl>, canopy_cover <dbl>, lon <dbl>, lat <dbl>, land_type <fct>Evaluation
- So far we have used
metricsandcollect_metricsto evaluate and compare models - The default metrics for classification problems are:
accuracy,brier_score,roc_auc- All classification metrics stem from the classic confusion matrix
. . .
- The default metrics for regression problems are:
rsq,rmse,mae- The majority of these are measures of correlation and residual error
Classification:
Confusion matrix
- A confusion matrix is a table that describes the performance of a classification model on a set of data for which the true values are known.
- It counts the number of accurate and false predictions, separated by the truth state
augment(forested_fit, new_data = forested_train) |>
conf_mat(truth = forested, estimate = .pred_class)
#> Truth
#> Prediction Yes No
#> Yes 2991 176
#> No 144 2374What to do with a confusion matrix

1. Accuracy
- Accuracy is the proportion of true results (both true positives and true negatives) among the total number of cases examined.
- It is a measure of the correctness of the model’s predictions.
- It is the most common metric used to evaluate classification models.
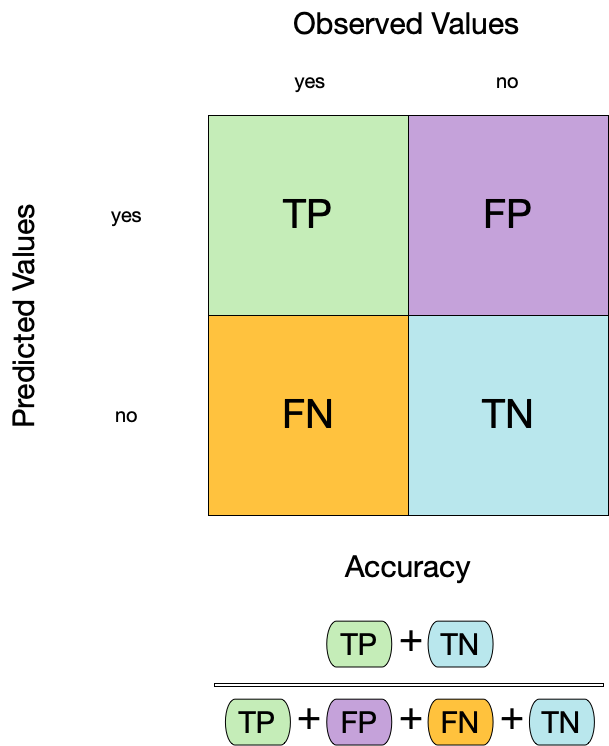
augment(forested_fit, new_data = forested_train) |>
accuracy(truth = forested, estimate = .pred_class)
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy binary 0.9442. Sensitivity
- Sensitivity is the proportion of true positives to the sum of true positives and false negatives.
- It is useful for identifying the presence of a condition.
- It is also known as the true positive rate, recall, or probability of detection.
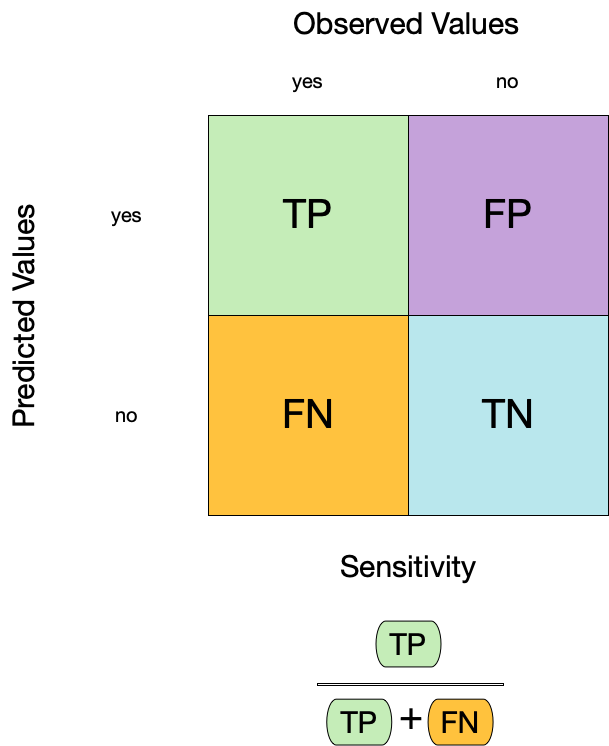
augment(forested_fit, new_data = forested_train) |>
sensitivity(truth = forested, estimate = .pred_class)
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 sensitivity binary 0.9543. Specificity
- Specificity is the proportion of true negatives to the sum of true negatives and false positives.
- It is useful for identifying the absence of a condition.
- It is also known as the true negative rate, and is the complement of sensitivity.
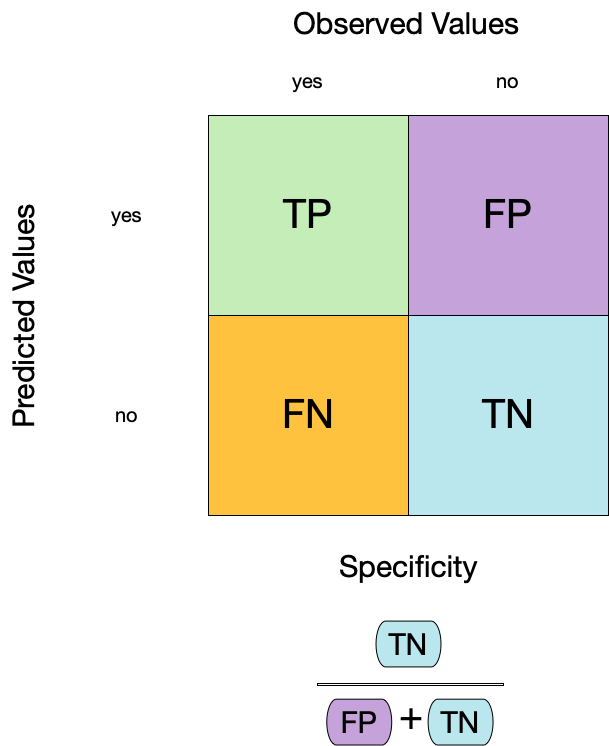
augment(forested_fit, new_data = forested_train) |>
specificity(truth = forested, estimate = .pred_class)
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 specificity binary 0.931Two class data
These metrics assume that we know the threshold for converting “soft” probability predictions into “hard” class predictions.
For example, if the predicted probability of a tree is 0.7, we might say that the model predicts “Tree” for that observation.
If the predicted probability of a tree is 0.4, we might say that the model predicts “No tree” for that observation.
The threshold is the value that separates the two classes.
The default threshold is 0.5, but this can be changed.
. . .
Is a 50% threshold good?
. . .
What happens if we say that we need to be 80% sure to declare an event?
- sensitivity ⬇️, specificity ⬆️
. . .
What happens for a 20% threshold?
- sensitivity ⬆️, specificity ⬇️
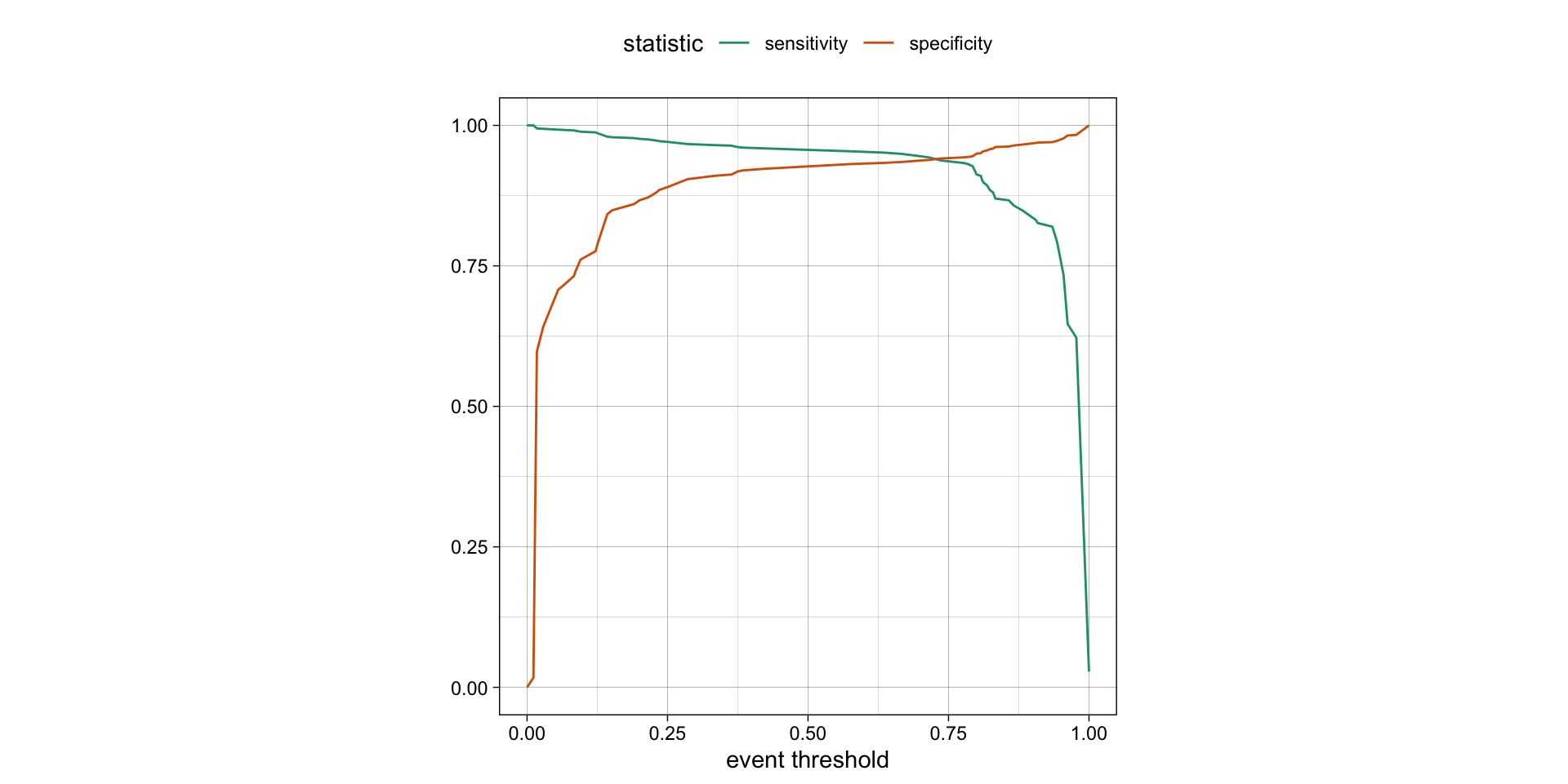
Varying the threshold
- The threshold can be varied to see how it affects the sensitivity and specificity of the model.
- This is done by plotting the sensitivity and specificity against the threshold.
- The threshold is varied from 0 to 1, and the sensitivity and specificity are calculated at each threshold.
- The plot shows the trade-off between sensitivity and specificity at different thresholds.
- The threshold can be chosen based on the desired balance between sensitivity and specificity.
ROC curves
For an ROC (receiver operator characteristic) curve, we plot
- the false positive rate (1 - specificity) on the x-axis
- the true positive rate (sensitivity) on the y-axis
with sensitivity and specificity calculated at all possible thresholds.
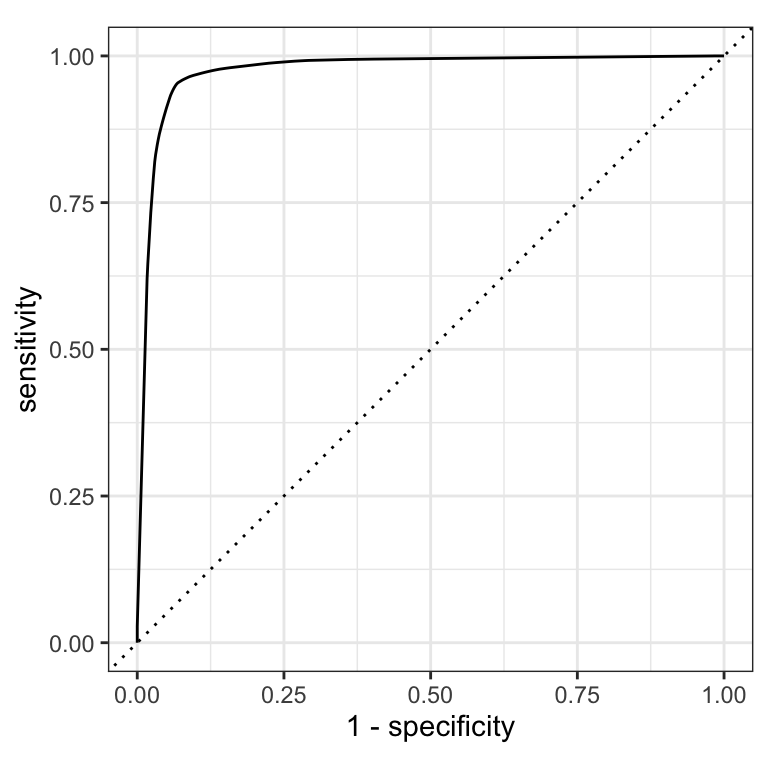
ROC curves
The ROC AUC is the probability that a randomly chosen positive instance is ranked higher than a randomly chosen negative instance.
The ROC AUC is a measure of how well the model separates the two classes.
The ROC AUC is a number between 0 and 1.
ROC AUC = 1 💯
- perfect classification
ROC AUC = 0.5 😐
- random guessing
ROC AUC < 0.5 😱
- worse than random guessing
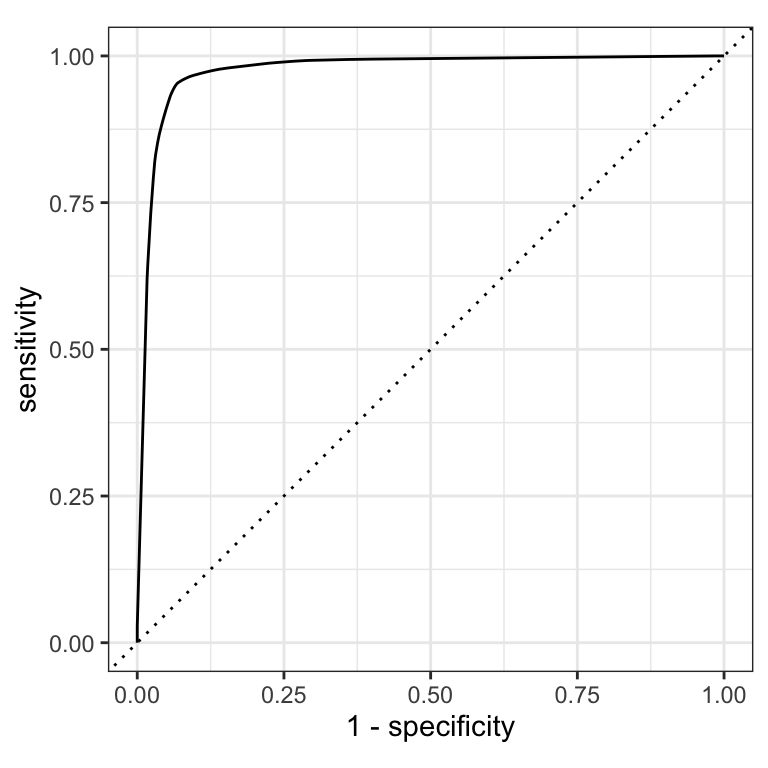
ROC curves
(A ROC AUC of 0.7-0.8 is considered acceptable, 0.8-0.9 is good, and >0.9 is excellent.)
# Assumes _first_ factor level is event; there are options to change that
augment(forested_fit, new_data = forested_train) |>
roc_curve(truth = forested, .pred_Yes) |>
dplyr::slice(1, 20, 50)
#> # A tibble: 3 × 3
#> .threshold specificity sensitivity
#> <dbl> <dbl> <dbl>
#> 1 -Inf 0 1
#> 2 0.235 0.885 0.972
#> 3 0.909 0.969 0.826
augment(forested_fit, new_data = forested_train) |>
roc_auc(truth = forested, .pred_Yes)
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 roc_auc binary 0.975Brier score
The Brier score is a measure of how well the predicted probabilities of an event match the actual outcomes.
It is the mean squared difference between predicted probabilities and actual outcomes.
The Brier score is a number between 0 and 1.
The Brier score is analogous to the mean squared error in regression models:
Brier = 1 😱
- predicted probabilities are completely wrong
Brier = 0.5 😐
- bad
Brier < 0.25
- acceptable
Brier = 0 💯
- predicted probabilities are perfect
\[ Brier_{class} = \frac{1}{N}\sum_{i=1}^N\sum_{k=1}^C (y_{ik} - \hat{p}_{ik})^2 \]
Brier score
augment(forested_fit, new_data = forested_train) |>
brier_class(truth = forested, .pred_Yes)
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 brier_class binary 0.0469Separation vs calibration
The ROC captures separation. - The ROC curve shows the trade-off between sensitivity and specificity at different thresholds.
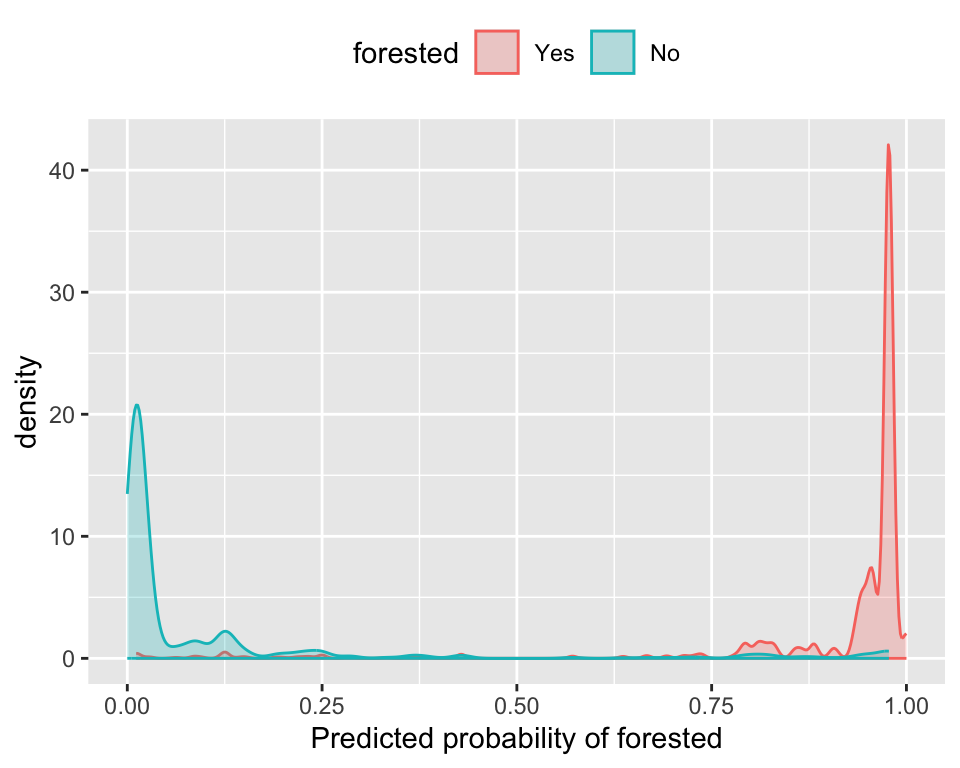
The Brier score captures calibration. - The Brier score is a measure of how well the predicted probabilities of an event match the actual outcomes.
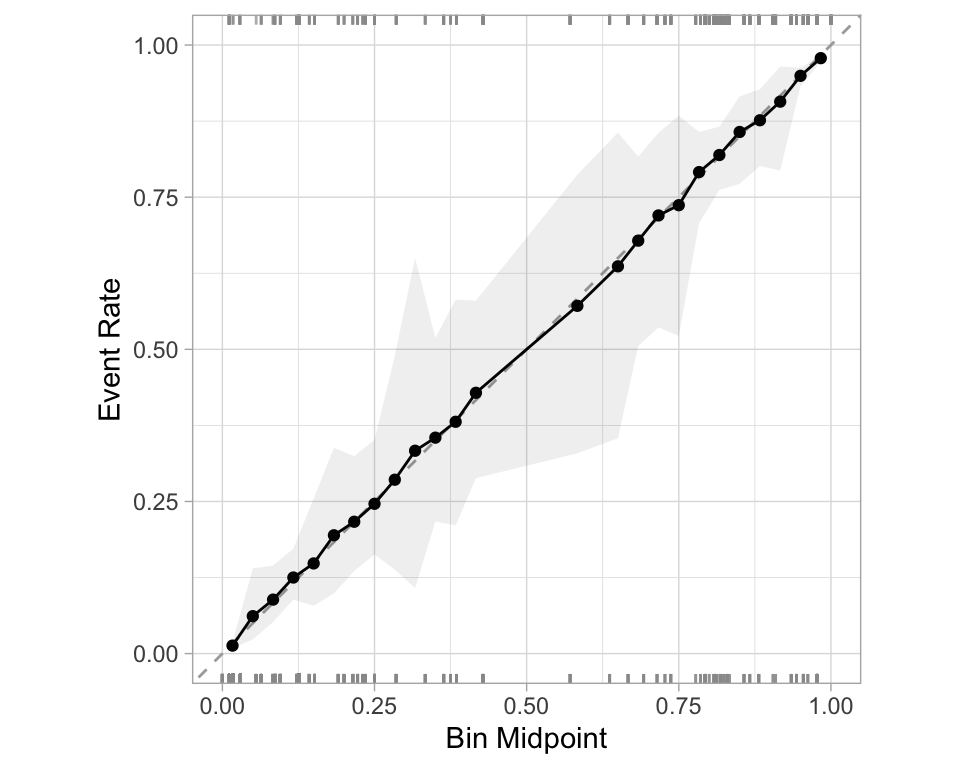
- Good separation: the densities don’t overlap.
- Good calibration: the calibration line follows the diagonal.
Calibration plot: We bin observations according to predicted probability. In the bin for 20%-30% predicted prob, we should see an event rate of ~25% if the model is well-calibrated.
Regression
R-squared (\(R^2\))
- Measures how well the model explains the variance in the data.
- Formula:
\[
R^2 = 1 - \frac{SS_{res}}{SS_{tot}}
\] where:
- \(SS_{res}\) is the sum of squared residuals.
\(SS_{tot}\) is the total sum of squares.
Values range from \(-\infty\) to 1.
- 1: Perfect fit
- 0: No improvement over mean prediction
- Negative: Worse than just using the mean
- 1: Perfect fit
Root Mean Squared Error (RMSE)
- Measures the model’s prediction error in the same unit as the dependent variable.
- Formula:
\[ RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} \]
where: - \(y_i\) is the actual value. - \(\hat{y}_i\) is the predicted value.
- Penalizes large errors more than MAE.
- Lower RMSE indicates better model performance.
Mean Absolute Error (MAE)
- Measures average absolute errors between predictions and actual values.
- Formula:
\[ MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| \]
- Less sensitive to outliers than RMSE.
- Lower MAE indicates better model performance.
Comparing Metrics
| Metric | Interpretation | Sensitivity to Outliers |
|---|---|---|
| \(R^2\) | Variance explained | Moderate |
| RMSE | Penalizes large errors more | High |
| MAE | Average error size | Low |
Choosing the Right Metric
- Use \(R^2\) to assess model fit and explainability.
- Use RMSE if large errors are especially undesirable.
- Use MAE for a more interpretable, robust metric.
Metrics Selection model performance
We can use metric_set() to combine multiple calculations into one
forested_metrics <- metric_set(accuracy, specificity, sensitivity)
augment(forested_fit, new_data = forested_train) |>
forested_metrics(truth = forested, estimate = .pred_class)
#> # A tibble: 3 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy binary 0.944
#> 2 specificity binary 0.931
#> 3 sensitivity binary 0.954. . .
Metrics and metric sets work with grouped data frames!
augment(forested_fit, new_data = forested_train) |>
group_by(tree_no_tree) |>
accuracy(truth = forested, estimate = .pred_class)
#> # A tibble: 2 × 4
#> tree_no_tree .metric .estimator .estimate
#> <fct> <chr> <chr> <dbl>
#> 1 Tree accuracy binary 0.946
#> 2 No tree accuracy binary 0.941
augment(forested_fit, new_data = forested_train) |>
group_by(tree_no_tree) |>
specificity(truth = forested, estimate = .pred_class)
#> # A tibble: 2 × 4
#> tree_no_tree .metric .estimator .estimate
#> <fct> <chr> <chr> <dbl>
#> 1 Tree specificity binary 0.582
#> 2 No tree specificity binary 0.974
Note
The specificity for "Tree" is a good bit lower than it is for "No tree".
So, when this index classifies the plot as having a tree, the model does not do well at correctly identifying the plot as non-forested when it is indeed non-forested.
Recap
Previously - Setup
library(tidyverse)
# Ingest Data
# URLs for COVID-19 case data and census population data
covid_url <- 'https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-states.csv'
pop_url <- '/Users/mikejohnson/github/csu-ess-330/resources/co-est2023-alldata.csv'
#pop_url <- 'https://www2.census.gov/programs-surveys/popest/datasets/2020-2023/counties/totals/co-est2023-alldata.csv'
# Clean Census Data
census = readr::read_csv(pop_url) |>
filter(COUNTY == "000") |> # Filter for state-level data only
mutate(fips = STATE) |> # Create a new FIPS column for merging
select(fips, contains("2021")) # Select relevant columns for 2021 data
# Process COVID-19 Data
state_data <- readr::read_csv(covid_url) |>
group_by(fips) |>
mutate(
new_cases = pmax(0, cases - dplyr::lag(cases)), # Compute new cases, ensuring no negative values
new_deaths = pmax(0, deaths - dplyr::lag(deaths)) # Compute new deaths, ensuring no negative values
) |>
ungroup() |>
left_join(census, by = "fips") |> # Merge with census data
mutate(
m = month(date), y = year(date),
season = case_when( # Define seasons based on month
m %in% 3:5 ~ "Spring",
m %in% 6:8 ~ "Summer",
m %in% 9:11 ~ "Fall",
m %in% c(12, 1, 2) ~ "Winter"
)
) |>
group_by(state, y, season) |>
mutate(
season_cases = sum(new_cases, na.rm = TRUE), # Aggregate seasonal cases
season_deaths = sum(new_deaths, na.rm = TRUE) # Aggregate seasonal deaths
) |>
distinct(state, y, season, .keep_all = TRUE) |> # Keep only distinct rows by state, year, season
ungroup() |>
select(state, contains('season'), y, POPESTIMATE2021, BIRTHS2021, DEATHS2021) |> # Select relevant columns
drop_na() |> # Remove rows with missing values
mutate(logC = log(season_cases +1)) # Log-transform case numbers for modelingPreviously - Data Usage
set.seed(4028)
split <- initial_split(state_data, prop = 0.8, strata = season) # 80/20 train-test split
train <- training(split) # Training set
test <- testing(split) # Test set
set.seed(3045)
folds <- vfold_cv(train, v = 10) # 10-fold cross-validationPreviously - Feature engineering 
rec = recipe(logC ~ . , data = train) |>
step_rm(state, season_cases) |> # Remove non-predictive columns
step_dummy(all_nominal()) |> # Convert categorical variables to dummy variables
step_scale(all_numeric_predictors()) |> # Scale numeric predictors
step_center(all_numeric_predictors()) Optimizing Models via Tuning Hyperparameter
Tuning parameters
Some model or preprocessing parameters cannot be estimated directly from the data.
Try different values and measure their performance.
. . .
- Find good values for these parameters.
. . .
- Once the value(s) of the parameter(s) are determined, a model can be finalized by fitting the model to the entire training set.
Tagging parameters for tuning 
With tidymodels, you can mark the parameters that you want to optimize with a value of tune().
The function itself just returns… itself:
tune()
#> tune()
str(tune())
#> language tune()
# optionally add a label
tune("Marker")
#> tune("Marker")Boosted Trees
In last weeks live demo, a boosted tree proved most effective.
Boosted Trees are popular ensemble methods that build a sequence of tree models.
Each tree uses the results of the previous tree to better predict samples, especially those that have been poorly predicted.
Each tree in the ensemble is saved and new samples are predicted using a weighted average of the votes of each tree in the ensemble.
Boosted Tree Tuning Parameters
Some possible parameters:
mtry: The number of predictors randomly sampled at each split (in \([1, ncol(x)]\) or \((0, 1]\)).trees: The number of trees (\([1, \infty]\), but usually up to thousands)min_n: The number of samples needed to further split (\([1, n]\)).learn_rate: The rate that each tree adapts from previous iterations (\((0, \infty]\), usual maximum is 0.1).stop_iter: The number of iterations of boosting where no improvement was shown before stopping (\([1, trees]\))
Boosted Tree Tuning Parameters
b_mod <-
boost_tree(trees = tune(), learn_rate = tune()) |>
set_mode("regression") |>
set_engine("xgboost")
(b_wflow <- workflow(rec, b_mod))
#> ══ Workflow ════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════
#> Preprocessor: Recipe
#> Model: boost_tree()
#>
#> ── Preprocessor ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
#> 4 Recipe Steps
#>
#> • step_rm()
#> • step_dummy()
#> • step_scale()
#> • step_center()
#>
#> ── Model ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
#> Boosted Tree Model Specification (regression)
#>
#> Main Arguments:
#> trees = tune()
#> learn_rate = tune()
#>
#> Computational engine: xgboostOptimize tuning parameters
The main two strategies for optimization are:
. . .
Grid search 💠 which tests a pre-defined set of candidate values
Iterative search 🌀 which suggests/estimates new values of candidate parameters to evaluate
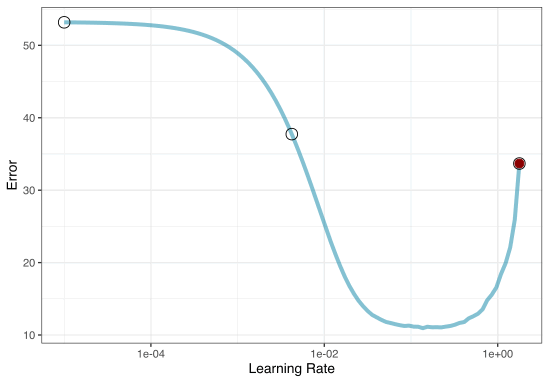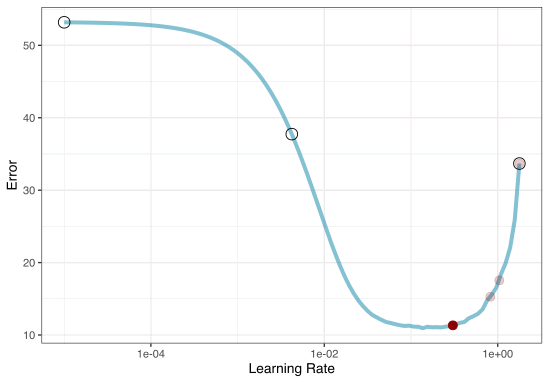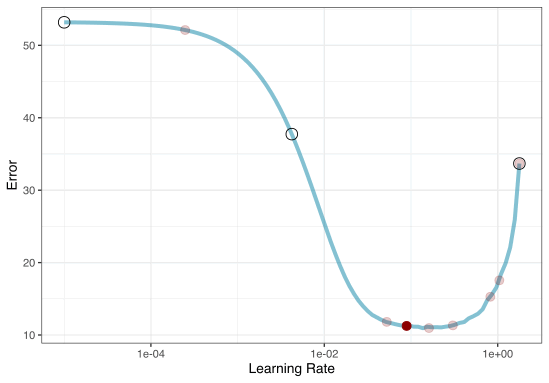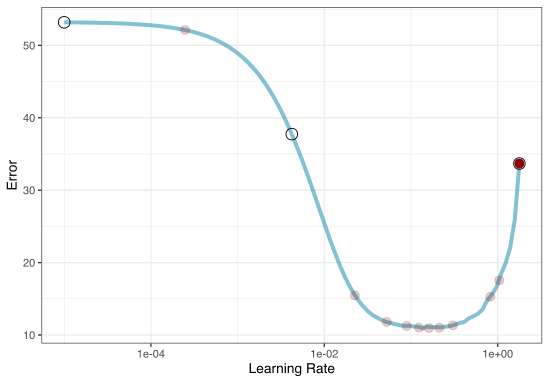
1. Grid search
Most basic (but very effective) way to tune models
A small grid of points trying to minimize the error via learning rate:

1. Grid search
In reality we would probably sample the space more densely:

2. Iterative Search
We could start with a few points and search the space:
Grid Search Example
Parameters
The tidymodels framework provides pre-defined information on tuning parameters (such as their type, range, transformations, etc).
The
extract_parameter_set_dials()function extracts these tuning parameters and the info.
Grids
Create your grid manually or automatically.
The
grid_*()functions can make a grid.
Different types of grids 
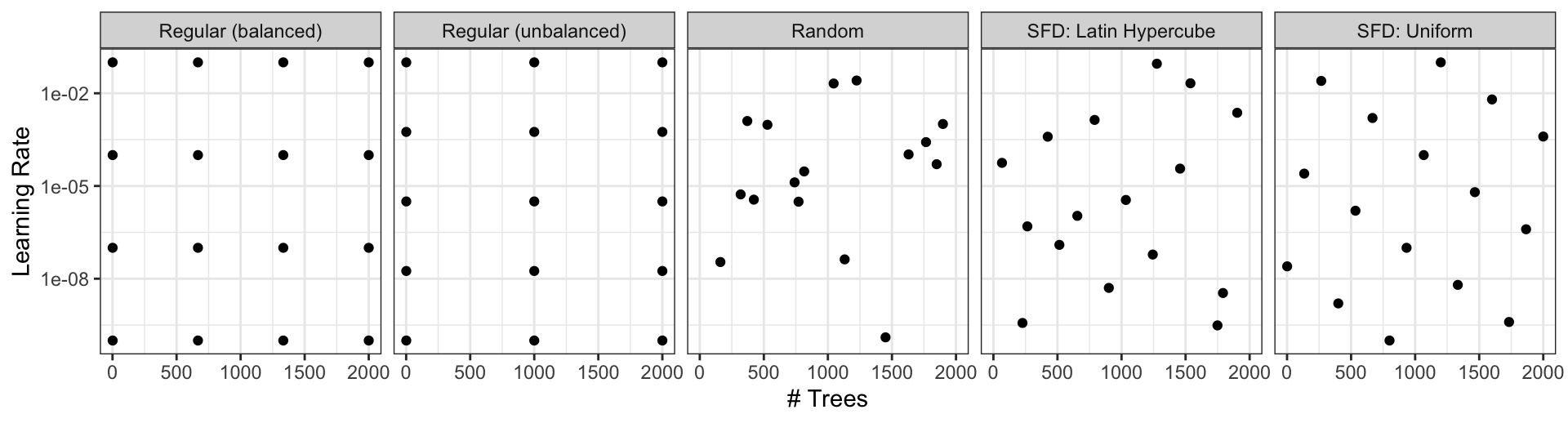
Space-filling designs (SFD) attempt to cover the parameter space without redundant candidates. We recommend these the most.
Create a grid
# Extac
(b_wflow |>
extract_parameter_set_dials())
# Individual functions:
(trees())
(learn_rate())A parameter set can be updated (e.g. to change the ranges).
Create a grid
- The
grid_*()functions create a grid of parameter values to evaluate. - The
grid_space_filling()function creates a space-filling design (SFD) of parameter values to evaluate. - The
grid_regular()function creates a regular grid of parameter values to evaluate. - The
grid_random()function creates a random grid of parameter values to evaluate. - The
grid_latin_hypercube()function creates a Latin hypercube design of parameter values to evaluate. - The
grid_max_entropy()function creates a maximum entropy design of parameter values to evaluate.
Create a SFD curve
set.seed(12)
(grid <-
b_wflow |>
extract_parameter_set_dials() |>
grid_space_filling(size = 25))
#> # A tibble: 25 × 2
#> trees learn_rate
#> <int> <dbl>
#> 1 1 0.0287
#> 2 84 0.00536
#> 3 167 0.121
#> 4 250 0.00162
#> 5 334 0.0140
#> 6 417 0.0464
#> 7 500 0.196
#> 8 584 0.00422
#> 9 667 0.00127
#> 10 750 0.0178
#> # ℹ 15 more rowsCreate a regular grid
set.seed(12)
(grid <-
b_wflow |>
extract_parameter_set_dials() |>
grid_regular(levels = 4))
#> # A tibble: 16 × 2
#> trees learn_rate
#> <int> <dbl>
#> 1 1 0.001
#> 2 667 0.001
#> 3 1333 0.001
#> 4 2000 0.001
#> 5 1 0.00681
#> 6 667 0.00681
#> 7 1333 0.00681
#> 8 2000 0.00681
#> 9 1 0.0464
#> 10 667 0.0464
#> 11 1333 0.0464
#> 12 2000 0.0464
#> 13 1 0.316
#> 14 667 0.316
#> 15 1333 0.316
#> 16 2000 0.316Update parameter ranges
b_param <-
b_wflow |>
extract_parameter_set_dials() |>
update(trees = trees(c(1L, 100L)),
learn_rate = learn_rate(c(-5, -1)))
set.seed(712)
(grid <-
b_param |>
grid_space_filling(size = 25))
#> # A tibble: 25 × 2
#> trees learn_rate
#> <int> <dbl>
#> 1 1 0.00215
#> 2 5 0.000147
#> 3 9 0.0215
#> 4 13 0.0000215
#> 5 17 0.000681
#> 6 21 0.00464
#> 7 25 0.0464
#> 8 29 0.0001
#> 9 34 0.0000147
#> 10 38 0.001
#> # ℹ 15 more rowsThe results 
grid |>
ggplot(aes(trees, learn_rate)) +
geom_point(size = 4) +
scale_y_log10()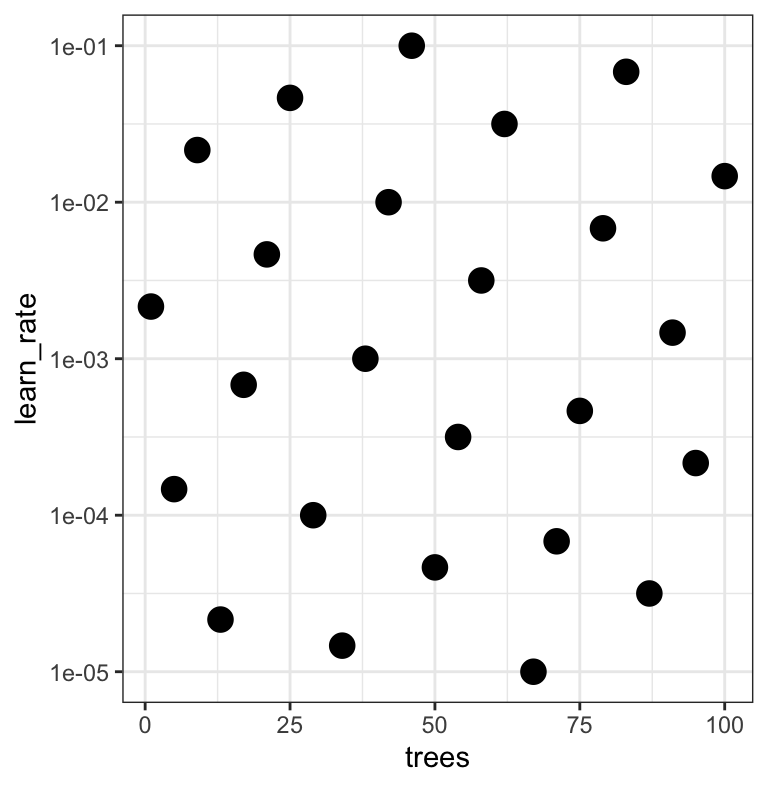
Note that the learning rates are uniform on the log-10 scale and this shows 2 of 4 dimensions.
Use the tune_*() functions to tune models
Choosing tuning parameters
Let’s take our previous model and tune more parameters:
Grid Search
tune_grid()is representative of tuning function syntax- similar to
fit_resamples()
Grid Search
b_res
#> # Tuning results
#> # 10-fold cross-validation
#> # A tibble: 10 × 5
#> splits id .metrics .notes .predictions
#> <list> <chr> <list> <list> <list>
#> 1 <split [513/57]> Fold01 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>
#> 2 <split [513/57]> Fold02 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>
#> 3 <split [513/57]> Fold03 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>
#> 4 <split [513/57]> Fold04 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>
#> 5 <split [513/57]> Fold05 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>
#> 6 <split [513/57]> Fold06 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>
#> 7 <split [513/57]> Fold07 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>
#> 8 <split [513/57]> Fold08 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>
#> 9 <split [513/57]> Fold09 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>
#> 10 <split [513/57]> Fold10 <tibble [25 × 7]> <tibble [0 × 3]> <tibble [1,425 × 7]>Grid results
autoplot(b_res)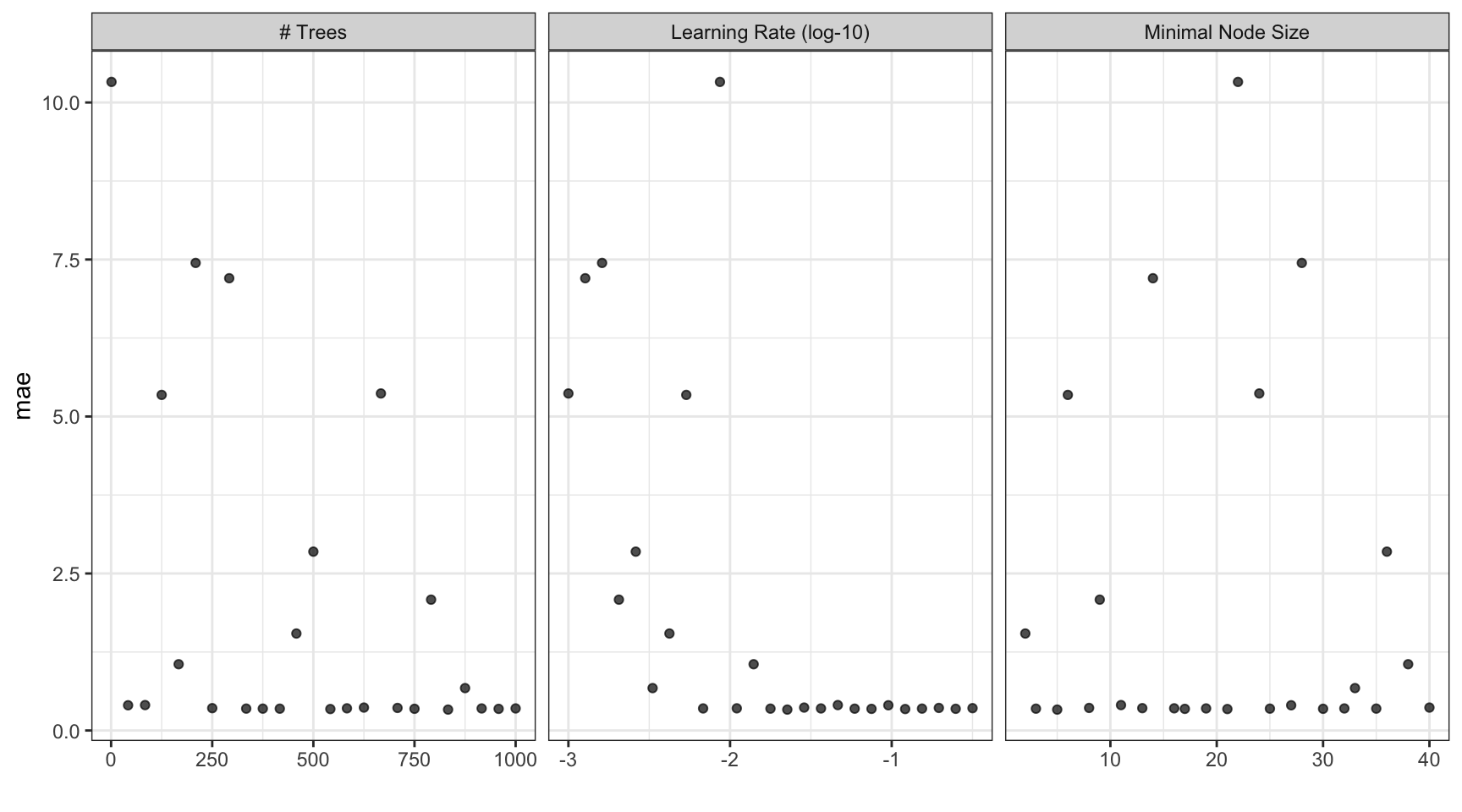
Tuning results
collect_metrics(b_res)
#> # A tibble: 25 × 9
#> trees min_n learn_rate .metric .estimator mean n std_err .config
#> <int> <int> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 458 2 0.00422 mae standard 1.54 10 0.0259 Preprocessor1_Model01
#> 2 417 3 0.0590 mae standard 0.347 10 0.0143 Preprocessor1_Model02
#> 3 833 5 0.0226 mae standard 0.333 10 0.0133 Preprocessor1_Model03
#> 4 125 6 0.00536 mae standard 5.34 10 0.0476 Preprocessor1_Model04
#> 5 708 8 0.196 mae standard 0.359 10 0.0120 Preprocessor1_Model05
#> 6 791 9 0.00205 mae standard 2.08 10 0.0300 Preprocessor1_Model06
#> 7 84 11 0.0464 mae standard 0.405 10 0.0186 Preprocessor1_Model07
#> 8 250 13 0.316 mae standard 0.356 10 0.0133 Preprocessor1_Model08
#> 9 292 14 0.00127 mae standard 7.20 10 0.0562 Preprocessor1_Model09
#> 10 583 16 0.0110 mae standard 0.353 10 0.0153 Preprocessor1_Model10
#> # ℹ 15 more rowsChoose a parameter combination
show_best(b_res, metric = "mae")
#> # A tibble: 5 × 9
#> trees min_n learn_rate .metric .estimator mean n std_err .config
#> <int> <int> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
#> 1 833 5 0.0226 mae standard 0.333 10 0.0133 Preprocessor1_Model03
#> 2 542 21 0.121 mae standard 0.342 10 0.0146 Preprocessor1_Model13
#> 3 958 17 0.0750 mae standard 0.344 10 0.0130 Preprocessor1_Model11
#> 4 750 30 0.249 mae standard 0.346 10 0.0123 Preprocessor1_Model19
#> 5 417 3 0.0590 mae standard 0.347 10 0.0143 Preprocessor1_Model02Choose a parameter combination
Create your own tibble for final parameters or use one of the tune::select_*() functions:
(b_best <- select_best(b_res, metric = "mae"))
#> # A tibble: 1 × 4
#> trees min_n learn_rate .config
#> <int> <int> <dbl> <chr>
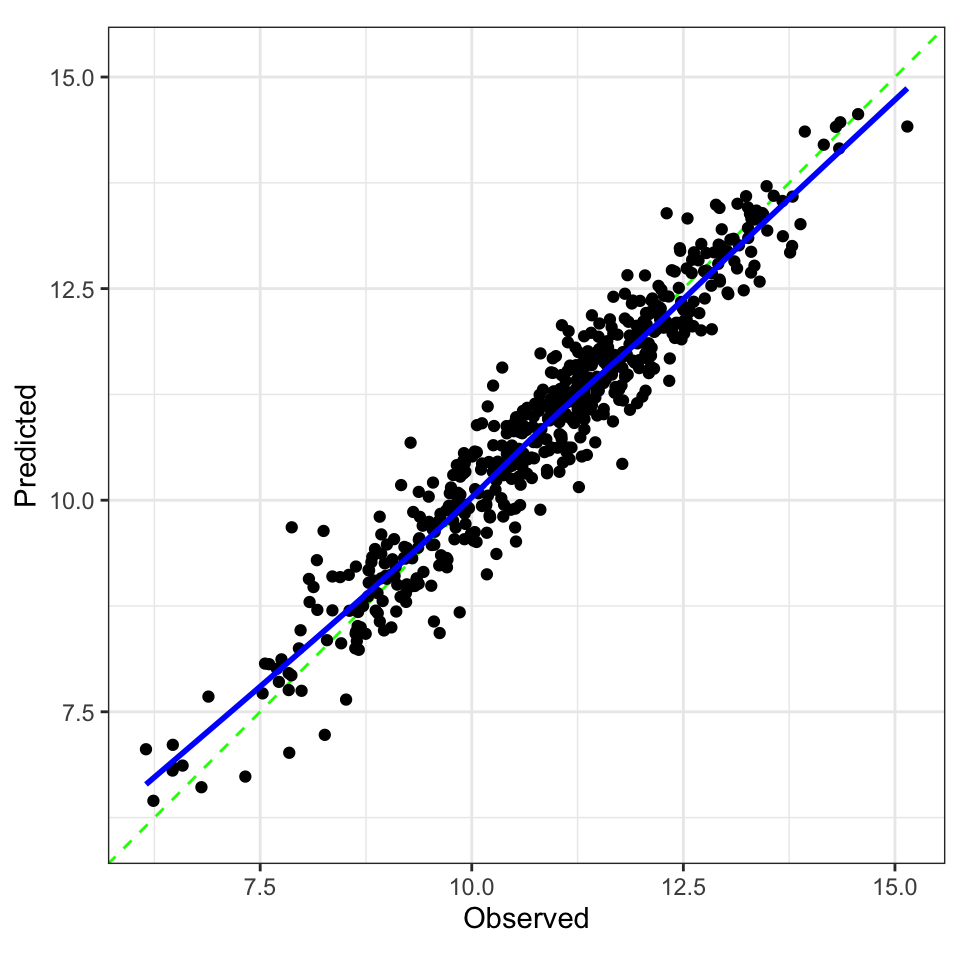
#> 1 833 5 0.0226 Preprocessor1_Model03Checking Calibration 
library(probably)
b_res |>
collect_predictions(
parameters = b_best
) |>
cal_plot_regression(
truth = logC,
estimate = .pred
)
The final fit!
Suppose that we are happy with our model.
Let’s fit the model on the training set and verify our performance using the test set.
. . .
We’ve seen fit() and predict() (+ augment()) but there is a shortcut:
. . .
# the boosted tree workflow can be `finalized` with the best parameters
workflow <- finalize_workflow(b_wflow, b_best)
# forested_split has train + test info
(final_fit <- last_fit(workflow, split))
#> # Resampling results
#> # Manual resampling
#> # A tibble: 1 × 6
#> splits id .metrics .notes .predictions .workflow
#> <list> <chr> <list> <list> <list> <list>
#> 1 <split [570/144]> train/test split <tibble [2 × 4]> <tibble [0 × 3]> <tibble [144 × 4]> <workflow>The final fit!
collect_metrics(final_fit)
#> # A tibble: 2 × 4
#> .metric .estimator .estimate .config
#> <chr> <chr> <dbl> <chr>
#> 1 rmse standard 0.391 Preprocessor1_Model1
#> 2 rsq standard 0.918 Preprocessor1_Model1
collect_predictions(final_fit) |>
ggplot(aes(.pred, logC)) +
geom_point() +
geom_abline() +
geom_smooth(method = "lm", se = FALSE)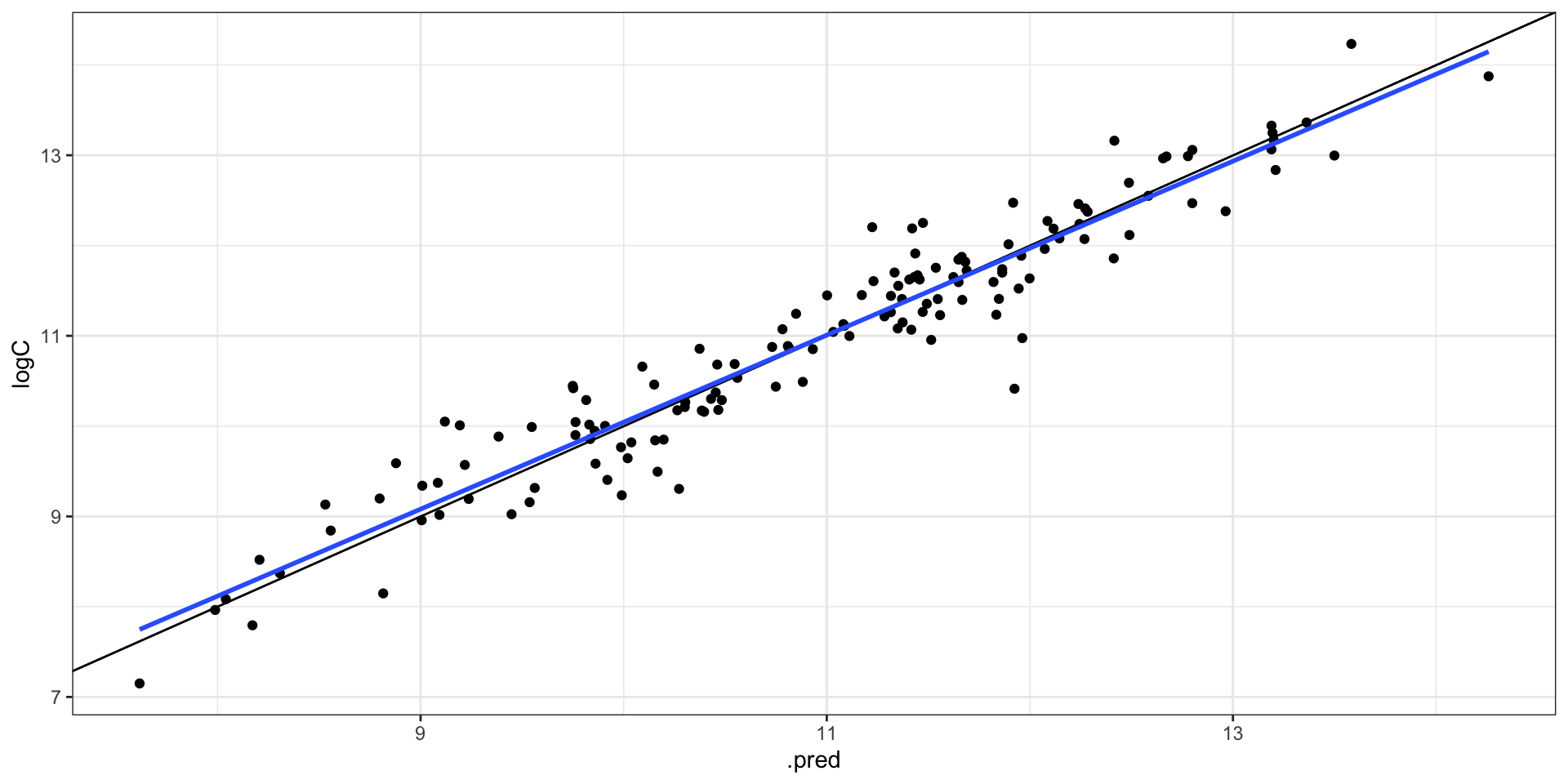
The whole game